
I started answering a question on SQL Community Slack’s #ssis channel and I realized this would be better served as a blog post. The question was about three SSIS Data Flow properties: DefaultBufferSize, Engine Thread and DefaultBufferMaxRows.
I rarely change the EngineThreads property.
DefaultBufferSize and DefaultBufferMaxRows are two ways of managing the size limits of a Data Flow buffer. The two Data Flow Task properties can – and should – be treated as a single property. DefaultBufferSize is the number of bytes per buffer. DefaultBufferMaxRows is the number of rows per buffer. The defaults are 10,485,760 (10M) and 10,000, respectively.
For source rows that are 1K in width it’s a wash because 10,000 rows * 1K == 10M.
The Dynamics
Let’s look at some implications of the math(s):
- If the source rows are wider than 1K, you will hit the 10M memory limit set by DefaultBufferSize before you encounter the DefaultBufferMaxRows limit.
- If the rows are less than 1K wide, you will hit the row count limit set by DefaultBufferMaxRows before you encounter the DefaultBufferSize limit.
- Together, these properties make up what I refer to as the Data Flow Task “Buffer Size” property.
When tuning a Data Flow Task I adjust both properties together by a similar factor because, in my little mind (at least), they are one property.
Extenuating Circumstances
As I share and demonstrate in the SQLSkills Immersion Event for Learning SSIS (IESSIS1 – next delivery in Chicago 7-11 May 2018) and the Brent Ozar Unlimited Expert SSIS (next deliveries 18-20 Jun and 10-12 Sep 2018), the data types, size, and shape of source data dramatically impact the performance of an SSIS Data Flow Task.
Data Types
It’s possible to mitigate for data types and I cover some ways to tune for the integration of BLOb data types in my series on Loading BLObs.
Data Size and Shape
As a function of the relationship between hard drive disk speeds (compounded by the fact that current systems were designed to work with spinning platters and read/write heads), RAM, and processor cache, the graph for moving “chunks” of data in any data movement operation (whether data or files) results in a curve*. In general, breaking an integration operation into ten chunks will almost always* perform the total load / move operation faster than loading / moving the same amount in a single operation. There is a point where the number of chunks results in a cursor-y operation. Here the performance curve trends downward (or upward, if you draw the graph like I do in my classes). The top (or bottom) of the curve represents maximum throughput for that size and shape of data containing the source data types.
Something to consider (I will not cover more in this post): The max-throughput can, and often almost always moves over time.
An Example
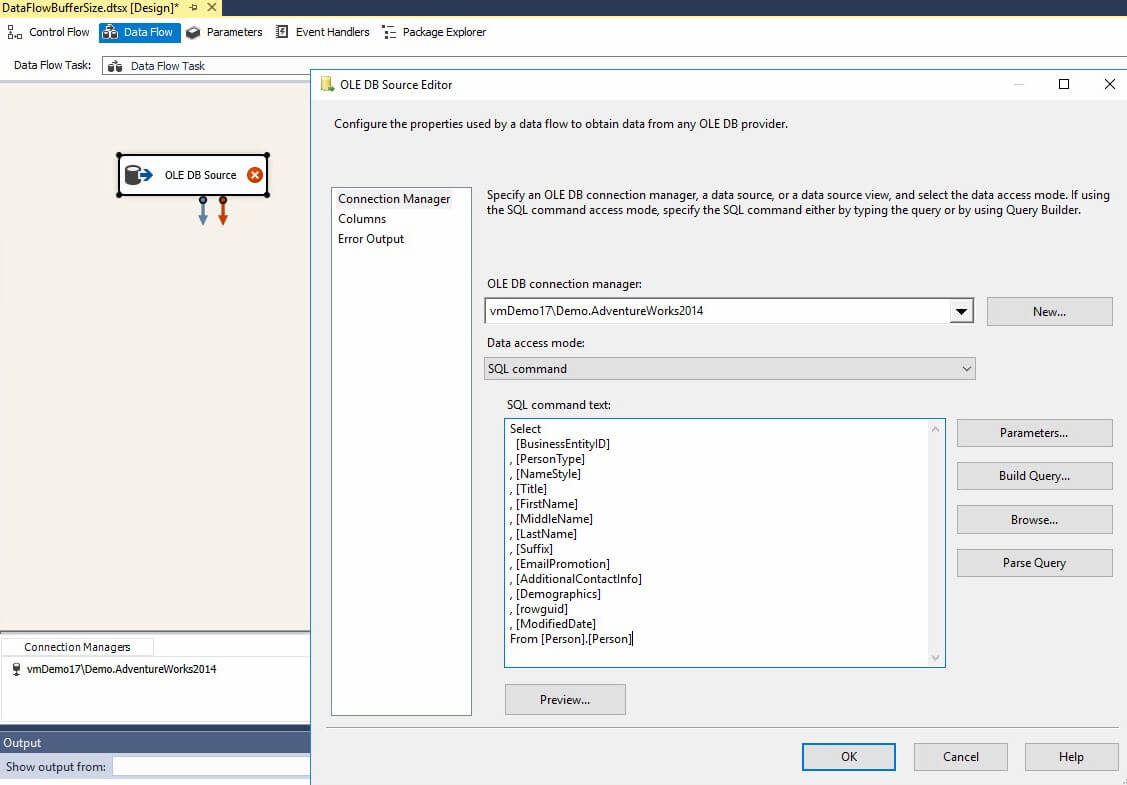
To demonstrate, I’ve created a sample SSIS project in SSDT v15.1.61801.210 for SSIS v14.0.3002.92 (Visual Studio 2017 for SSIS 2017). I select from the AdventureWorks2014 Person.Person table using an OLE DB Source adapter (click to enlarge):
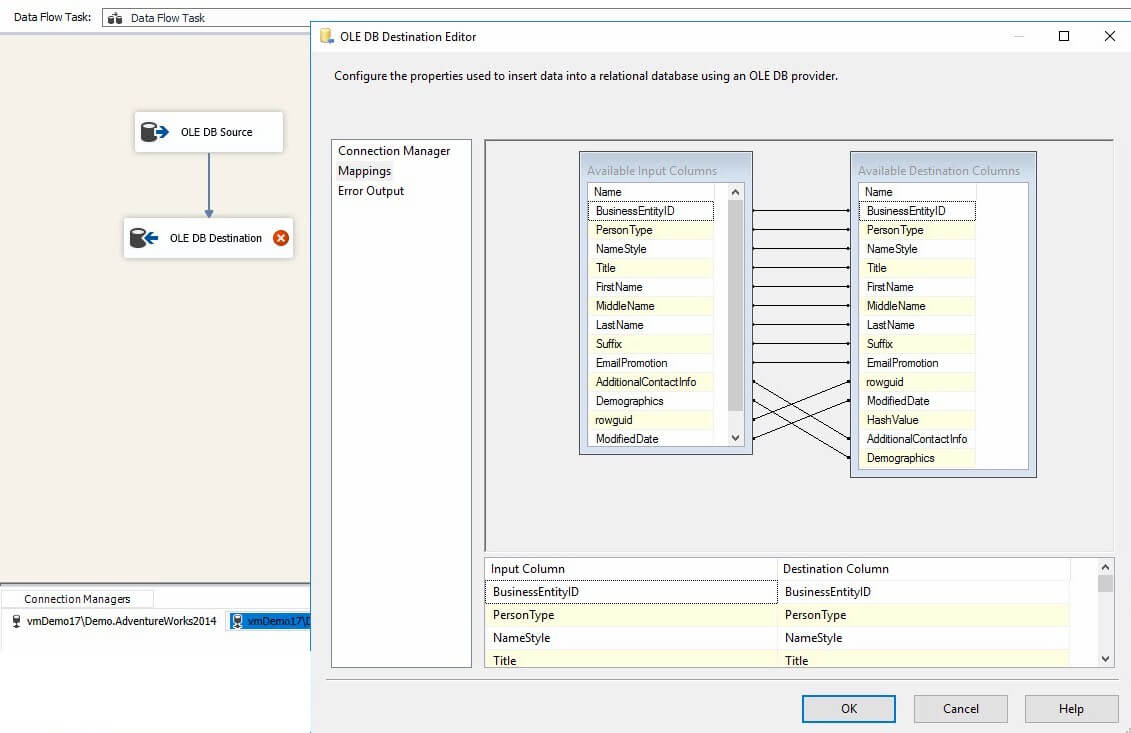
I map to an almost identical table – via an OLE DB Destination adapter – in a test database (named TestDB) on the same instance of SQL Server:
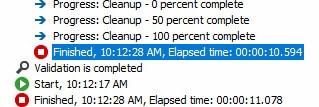
Executing with the defaults (10,000 rows for DefaultBufferMaxRows and 10M for DefaultBufferSize), the Data Flow Task executes in 10.594 seconds:
Dropping the Buffer Size properties an order of magnitude…

… results in an execution time of 6.328 seconds:
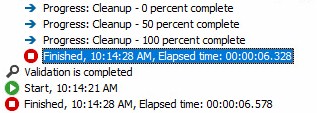
For those curious about the effects of queuing, returning the properties to 10,000 and 10,485,760 results in an execution time of 9.61 seconds on my demo VM.
Your mileage may vary.
Conclusion
In this post, I’ve briefly discussed and demonstrated one impact of managing SSIS Data Flow Task performance by adjusting the Buffer Size properties – DefaultBufferMaxRows and DefaultBufferSize.
:{>
*Intentionally equivocal language in use… caveats abound.
Learn More from Me!
Check out training at Enterprise Data & Analytics!
Hi Andy,
I am Dominic. I am a BI developer at Nexcel Solution.
May I join https://sqlcommunity.slack.com ?
Hi Dominic,
I think anyone may join.
:{>