

Recently, I was developing an SSIS package that read from an Azure SQL DB table and wrote to an on-premises SQL Server 2025 database table. I encountered the following error: [ADO NET Source [41]] Error: ADO NET Source has failed to acquire the connection {<ConnectionManagerGUID>} with the following error message: “Could not load file or …
Continue reading SSIS 2025 Microsoft.Data.SqlClient Connection Error
Author:Andy Leonard
Christian, husband, dad, grandpa, Data Philosopher, Data Engineer; Azure Data Factory, Fabric Data Factory, and SSIS guy; and farmer. I was cloud before cloud was cool. :{>
Twenty years of watching SSIS catalog drift, environment mismatches, and deployment chaos finally has a name: Data Integration Lifecycle Management. I build tools for it at DILM Suite. Start with SSIS Catalog Compare.
Remigration – T-SQL Tuesday #199

This month’s T-SQL Tuesday is hosted by Koen Verbeeck (sqlkover.com, LinkedIn, @Ko_Ver). The topic is remigration, or moving from the cloud back to on-premises or a private data center. Migration As a data engineering consultant, I’ve helped many customers migrate from on-premises to the cloud. Because my experience lies in the Microsoft data sphere, nearly …
Continue reading Remigration – T-SQL Tuesday #199
Install and Configure SQL Server 2025 Enterprise Developer Edition

This post is for people interested in setting up an instance of SQL Server 2025 Enterprise Developer Edition for personal use. I caution those interested in configuring an instance of SQL Server 2025 Enterprise for production purposes: You should not use Developer Edition because it’s not for production workloads by design and according to the …
Continue reading Install and Configure SQL Server 2025 Enterprise Developer Edition
Download SQL Server 2025 Enterprise Developer Edition
This post is for people interested in setting up an instance of SQL Server 2025 Enterprise Developer Edition for personal use. If you are interested in configuring an instance of SQL Server 2025 for production purposes, you should not use Enterprise Developer Edition – it’s not for production workloads by design and according to the …
Continue reading Download SQL Server 2025 Enterprise Developer Edition
One Way to Install SQL Server 2025 Enterprise Developer Edition
In this series, I walk through one way to install and configure SQL Server 2025 Enterprise Developer Edition. This series is not intended as guidance for production environments. This series is simply one way I install and configure SQL Server 2025 Enterprise for my test and exploration environment. Download SQL Server 2025 Enterprise Developer Edition …
Continue reading One Way to Install SQL Server 2025 Enterprise Developer Edition
Microsoft Just Made SSIS-to-Fabric Easier
Upcoming Live Training A Day of Fabric Data Factory | 19 May 2026 | Live online, 9:00 AM to 4:30 PM EDT Registration closes 16 May 2026 Register → Here’s what “easier” means Your SSIS packages still pay the bills. They’ve earned that. The orchestration logic, the error handling, the parameter discipline, the framework patterns …
Continue reading Microsoft Just Made SSIS-to-Fabric Easier
SSIS Extension Updates – Apr 2026

Back in June 2024, I announced I was changing the way I report updates to the SQL Server Integration Services extension for Visual Studio (in a post titled SSIS Extension Updates – Jun 2024). I have a calendar reminder that reminds me to check the links every quarter, and that reminder did its job admirably …
Continue reading SSIS Extension Updates – Apr 2026
The Day Our SSIS Catalogs Didn’t Match

I knew what I was doing. I wrote the lifecycle management chapter in the Wrox SSIS 2005 book. I implemented SSIS lifecycle management at Unisys. We’d done everything by the book. Well, by the books. This book and this book. In 2013, I led a team that designed an SSIS project that included over 300 …
Continue reading The Day Our SSIS Catalogs Didn’t Match
Fabric SSIS Public Preview: What It Changes – and What It Doesn’t
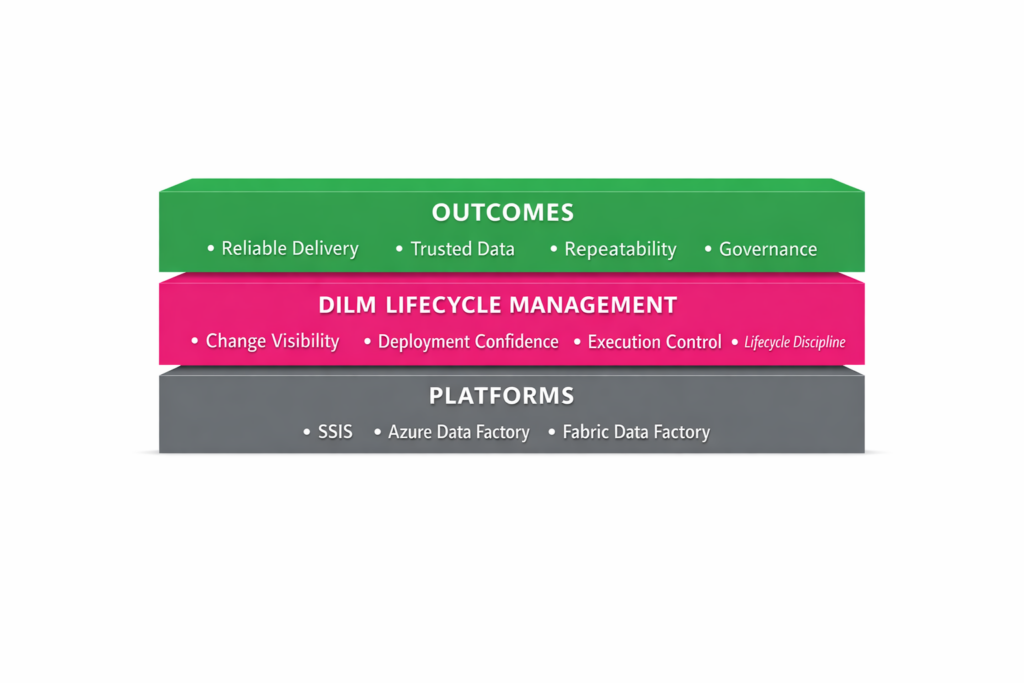
The conversation around SSIS is heating up again.
Some see the signals and conclude SSIS is on the way out. Others point to the strength of the ecosystem and say it is far from done.
Both perspectives miss something important.
The introduction of Fabric SSIS public preview does not settle the debate. It reframes it.
Use SSIS Framework Manager to Build an SSIS Application

The Data Integration Lifecycle Management Suite (DILM Suite) is a collection of tools designed to reduce the friction of managing SQL Server Integration Services (SSIS) across its lifecycle. The SSIS Framework is a core element of DILM Suite. About DILM Suite DILM Suite helps enterprise data engineers and data teams compare, package, deploy, and maintain …
Continue reading Use SSIS Framework Manager to Build an SSIS Application