
|
Update: For more up-to-date material on this topic, please see the Stairway to Incremental Loads at SQL Server Central for more information! (Free registration required).
Introduction
Loading data from a data source to SQL Server is a common task. It’s used in Data Warehousing, but increasingly data is being staged in SQL Server for non-Business-Intelligence purposes.
Maintaining data integrity is key when loading data into any database. A common way of accomplishing this is to truncate the destination and reload from the source. While this method ensures data integrity, it also loads a lot of data that was just deleted.
Incremental loads are a faster and use less server resources. Only new or updated data is touched in an incremental load.
When To Use Incremental Loads
Use incremental loads whenever you need to load data from a data source to SQL Server.
Incremental loads are the same regardless of which database platform or ETL tool you use. You need to detect new and updated rows – and separate these from the unchanged rows.
Incremental Loads in Transact-SQL
I will start by demonstrating this with T-SQL:
0. (Optional, but recommended) Create two databases: a source and destination database for this demonstration:
CREATE DATABASE [SSISIncrementalLoad_Source] CREATE DATABASE [SSISIncrementalLoad_Dest] 1. Create a source named tblSource with the columns ColID, ColA, ColB, and ColC; make ColID is a primary unique key:
USE SSISIncrementalLoad_Source
GO
CREATE TABLE dbo.tblSource
(ColID int NOT NULL
,ColA varchar(10) NULL
,ColB datetime NULL constraint df_ColB default (getDate())
,ColC int NULL
,constraint PK_tblSource primary key clustered (ColID))
2. Create a Destination table named tblDest with the columns ColID, ColA, ColB, ColC:
USE SSISIncrementalLoad_Dest
GO CREATE TABLE dbo.tblDest (ColID int NOT NULL ,ColA varchar(10) NULL ,ColB datetime NULL ,ColC int NULL) 3. Let’s load some test data into both tables for demonstration purposes:
USE SSISIncrementalLoad_Source
GO — insert an “unchanged” row — insert a “changed” row — insert a “new” row USE SSISIncrementalLoad_Dest — insert an “unchanged” row — insert a “changed” row 4. You can view new rows with the following query: SELECT s.ColID, s.ColA, s.ColB, s.ColC This should return the “new” row – the one loaded earlier with ColID = 2 and ColA = ‘N’. Why? The LEFT JOIN and WHERE clauses are the key. Left Joins return all rows on the left side of the join clause (SSISIncrementalLoad_Source.dbo.tblSource in this case) whether there’s a match on the right side of the join clause (SSISIncrementalLoad_Dest.dbo.tblDest in this case) or not. If there is no match on the right side, NULLs are returned. This is why the WHERE clause works: it goes after rows where the destination ColID is NULL. These rows have no match in the LEFT JOIN, therefore they must be new. This is only an example. You occasionally find database schemas that are this easy to load. Occasionally. Most of the time you have to include several columns in the JOIN ON clause to isolate truly new rows. Sometimes you have to add conditions in the WHERE clause to refine the definition of truly new rows. Incrementally load the row (“rows” in practice) with the following T-SQL statement: INSERT INTO SSISIncrementalLoad_Dest.dbo.tblDest 5. There are many ways by which people try to isolate changed rows. The only sure-fire way to accomplish it is to compare each field. View changed rows with the following T-SQL statement: SELECT d.ColID, d.ColA, d.ColB, d.ColC This should return the “changed” row we loaded earlier with ColID = 1 and ColA = ‘C’. Why? The INNER JOIN and WHERE clauses are to blame – again. The INNER JOIN goes after rows with matching ColID’s because of the JOIN ON clause. The WHERE clause refines the resultset, returning only rows where the ColA’s, ColB’s, or ColC’s don’t match and the ColID’s match. This is important. If there’s a difference in any or some or all the rows (except ColID), we want to update it. Extract-Transform-Load (ETL) theory has a lot to say about when and how to update changed data. You will want to pick up a good book on the topic to learn more about the variations. To update the data in our destination, use the following T-SQL: UPDATE d Incremental Loads in SSIS
Let’s take a look at how you can accomplish this in SSIS using the Lookup Transformation (for the join functionality) combined with the Conditional Split (for the WHERE clause conditions) transformations.
Before we begin, let’s reset our database tables to their original state using the following query:
USE SSISIncrementalLoad_Source TRUNCATE TABLE dbo.tblSource — insert an “unchanged” row — insert a “changed” row — insert a “new” row USE SSISIncrementalLoad_Dest TRUNCATE TABLE dbo.tblDest — insert an “unchanged” row — insert a “changed” row Next, create a new project using Business Intelligence Development Studio (BIDS). Name the project SSISIncrementalLoad:
Once the project loads, open Solution Explorer and rename Package1.dtsx to SSISIncrementalLoad.dtsx:
When prompted to rename the package object, click the Yes button. From the toolbox, drag a Data Flow onto the Control Flow canvas:
Double-click the Data Flow task to edit it. From the toolbox, drag and drop an OLE DB Source onto the Data Flow canvas:
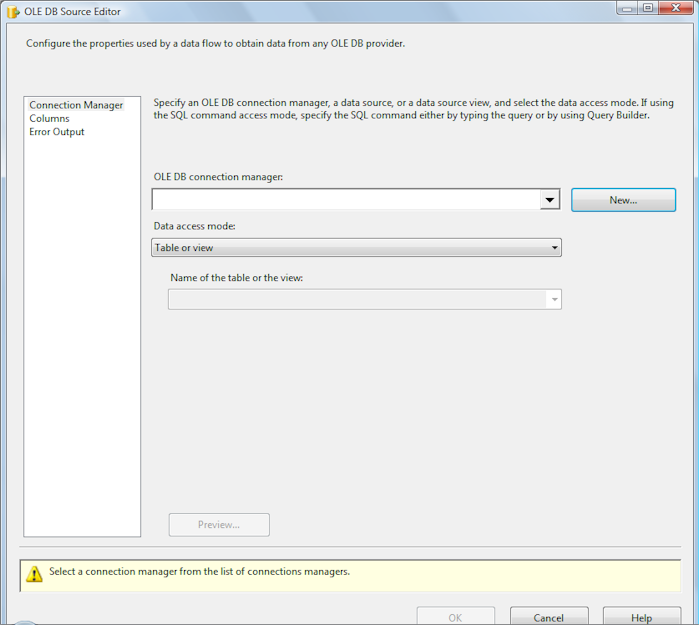
Double-click the OLE DB Source connection adapter to edit it:
Click the New button beside the OLE DB Connection Manager dropdown:
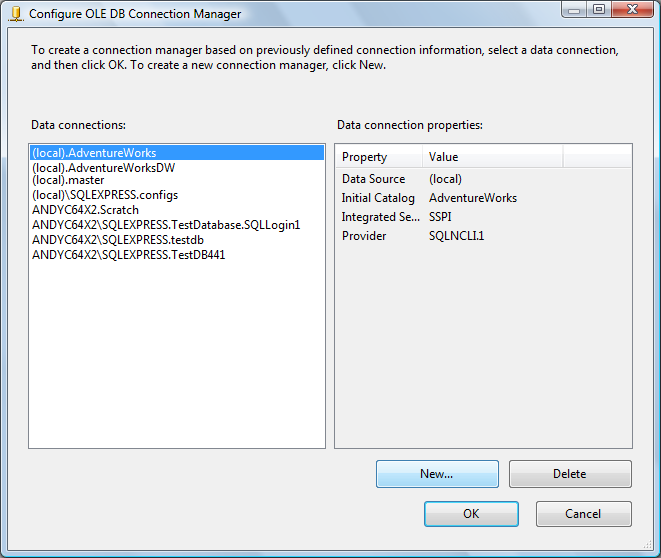
Click the New button here to create a new Data Connection:
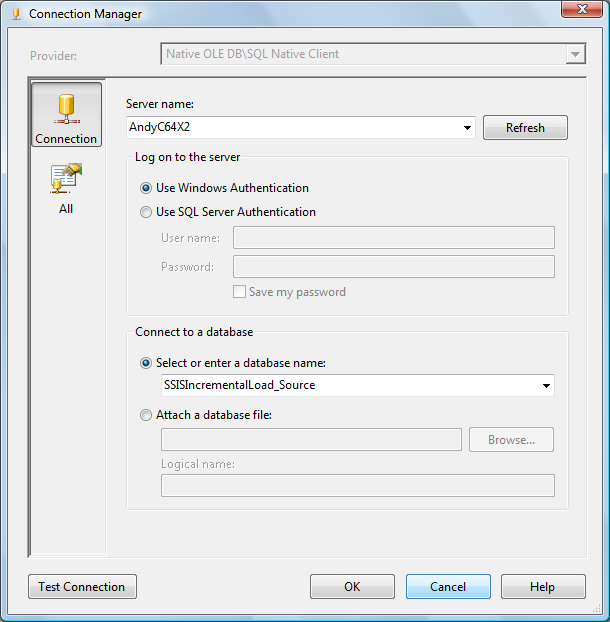
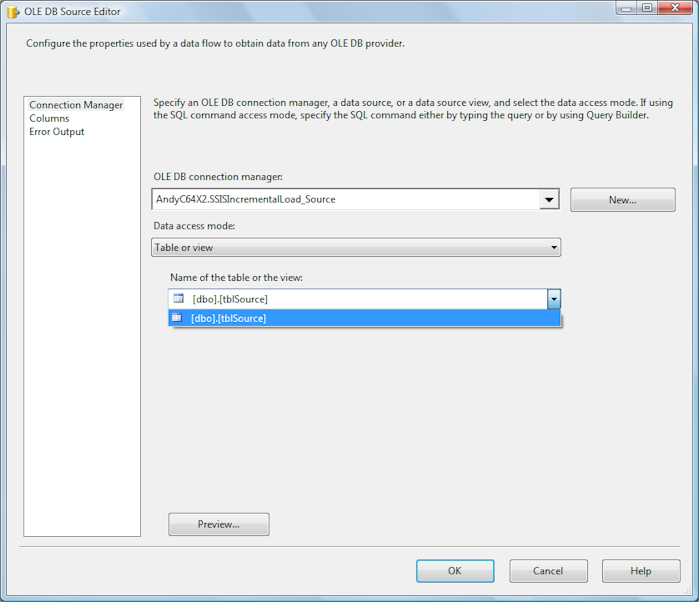
Enter or select your server name. Connect to the SSISIncrementalLoad_Source database you created earlier. Click the OK button to return to the Connection Manager configuration dialog. Click the OK button to accept your newly created Data Connection as the Connection Manager you wish to define. Select “dbo.tblSource” from the Table dropdown:
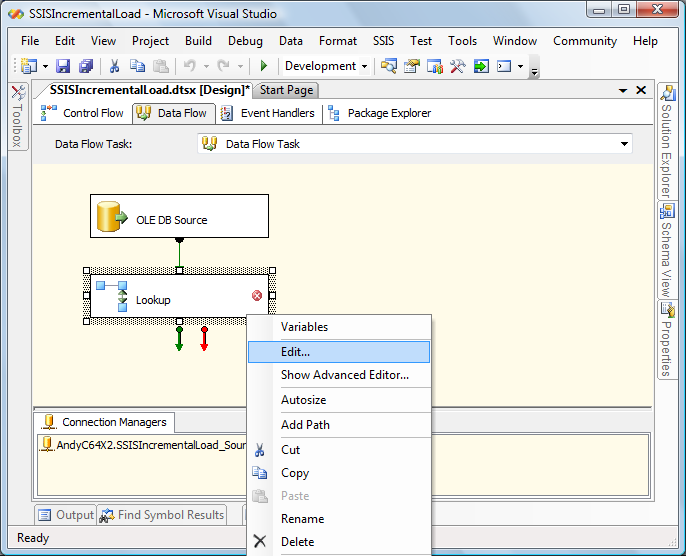
Click the OK button to complete defining the OLE DB Source Adapter. Drag and drop a Lookup Transformation from the toolbox onto the Data Flow canvas. Connect the OLE DB connection adapter to the Lookup transformation by clicking on the OLE DB Source and dragging the green arrow over the Lookup and dropping it. Right-click the Lookup transformation and click Edit (or double-click the Lookup transformation) to edit:
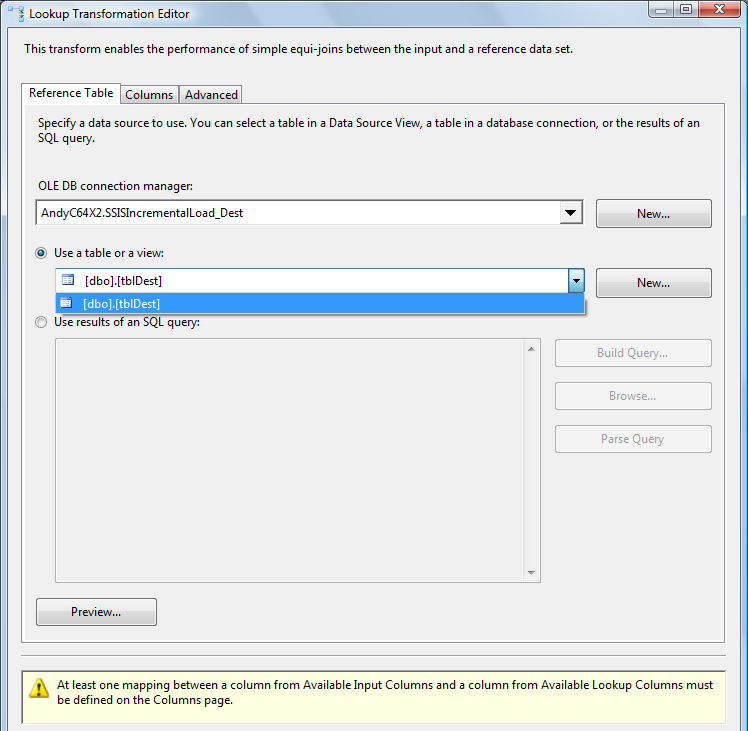
When the editor opens, click the New button beside the OLE DB Connection Manager dropdown (as you did earlier for the OLE DB Source Adapter). Define a new Data Connection – this time to the SSISIncrementalLoad_Dest database. After setting up the new Data Connection and Connection Manager, configure the Lookup transformation to connect to “dbo.tblDest”:
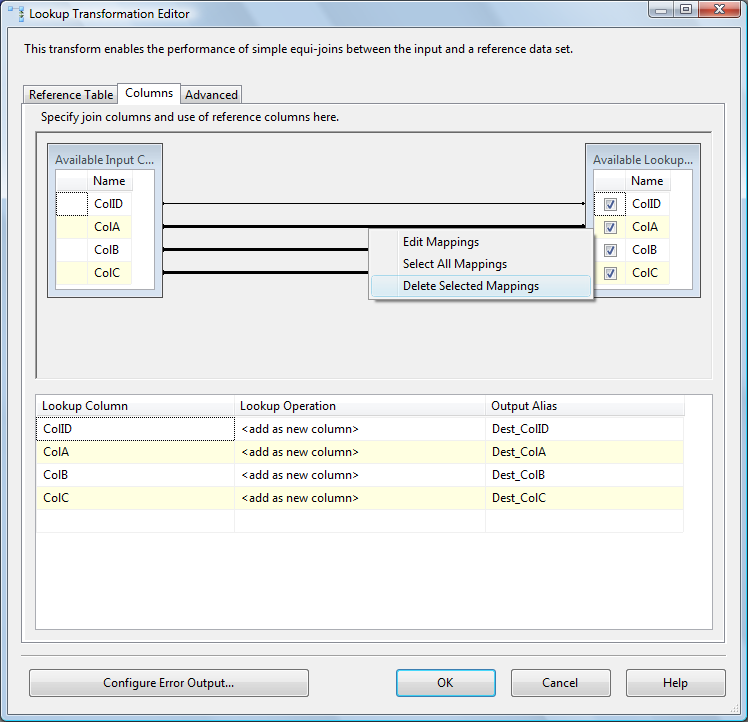
Click the Columns tab. On the left side are the columns currently in the SSIS data flow pipeline (from SSISIncrementalLoad_Source.dbo.tblSource). On the right side are columns available from the Lookup destination you just configured (from SSISIncrementalLoad_Dest.dbo.tblDest). Follow the following steps: 1. We’ll need all the rows returned from the destination table, so check all the checkboxes beside the rows in the destination. We need these rows for our WHERE clauses and for our JOIN ON clauses. 2. We do not want to map all the rows between the source and destination – we only want to map the columns named ColID between the database tables. The Mappings drawn between the Available Input Columns and Available Lookup Columns define the JOIN ON clause. Multi-select the Mappings between ColA, ColB, and ColC by clicking on them while holding the Ctrl key. Right-click any of them and click “Delete Selected Mappings” to delete these columns from our JOIN ON clause. 3. Add the text “Dest_” to each column’s Output Alias. These rows are being appended to the data flow pipeline. This is so we can distinguish between Source and Destination rows farther down the pipeline:
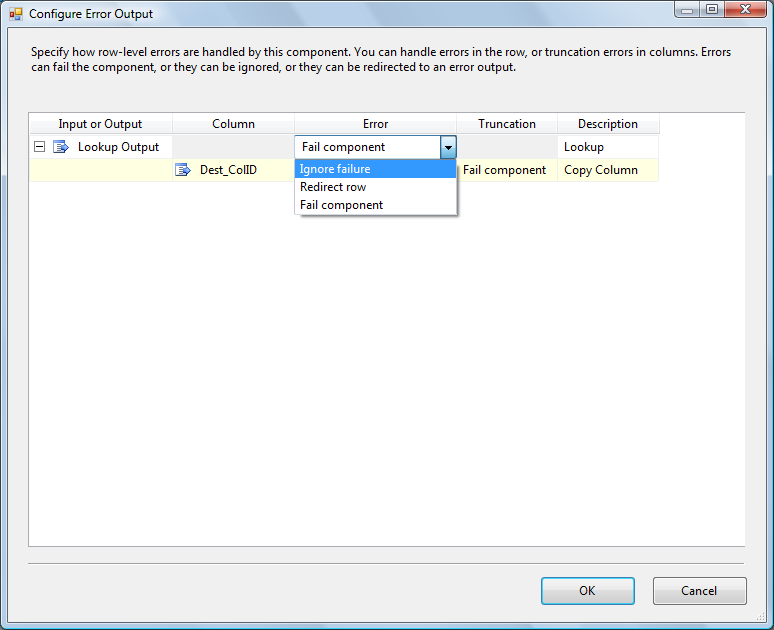
Next we need to modify our Lookup transformation behavior. By default, the Lookup operates as an INNER JOIN – but we need a LEFT (OUTER) JOIN. Click the “Configure Error Output” button to open the “Configure Error Output” screen. On the “Lookup Output” row, change the Error column from “Fail component” to “Ignore failure”. This tells the Lookup transformation “If you don’t find an INNER JOIN match in the destination table for the Source table’s ColID value, don’t fail.” – which also effectively tells the Lookup “Don’t act like an INNER JOIN, behave like a LEFT JOIN”:
Click OK to complete the Lookup transformation configuration. From the toolbox, drag and drop a Conditional Split Transformation onto the Data Flow canvas. Connect the Lookup to the Conditional Split as shown. Right-click the Conditional Split and click Edit to open the Conditional Split Editor:
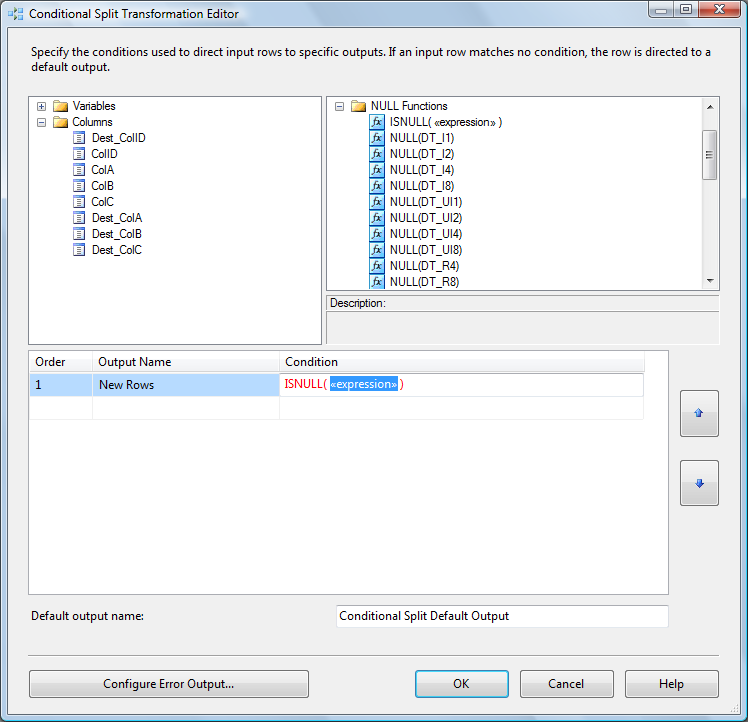
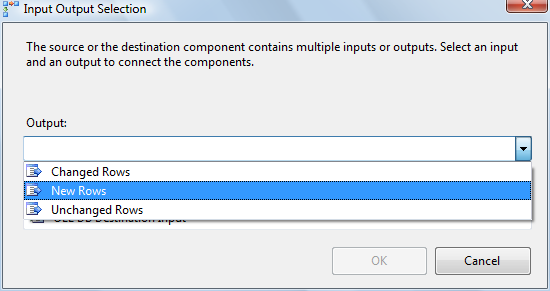
Expand the NULL Functions folder in the upper right of the Conditional Split Transformation Editor. Expand the Columns folder in the upper left side of the Conditional Split Transformation Editor. Click in the “Output Name” column and enter “New Rows” as the name of the first output. From the NULL Functions folder, drag and drop the “ISNULL( <<expression>> )” function to the Condition column of the New Rows condition:
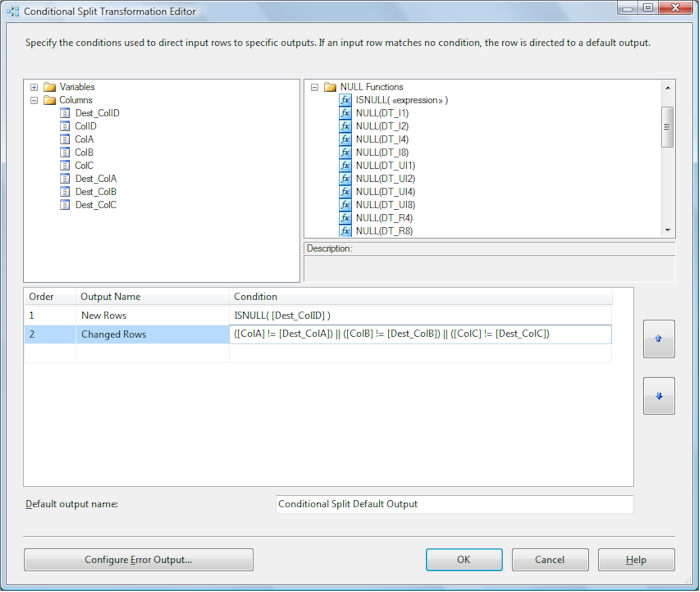
Next, drag Dest_ColID from the columns folder and drop it onto the “<<expression>>” text in the Condition column. “New Rows” should now be defined by the condition “ISNULL( [Dest_ColID] )”. This defines the WHERE clause for new rows – setting it to “WHERE Dest_ColID Is NULL”. Type “Changed Rows” into a second Output Name column. Add the expression “(ColA != Dest_ColA) || (ColB != Dest_ColB) || (ColC != Dest_ColC)” to the Condition column for the Changed Rows output. This defines our WHERE clause for detecting changed rows – setting it to “WHERE ((Dest_ColA != ColA) OR (Dest_ColB != ColB) OR (Dest_ColC != ColC))”. Note “||” is used to convey “OR” in SSIS Expressions:
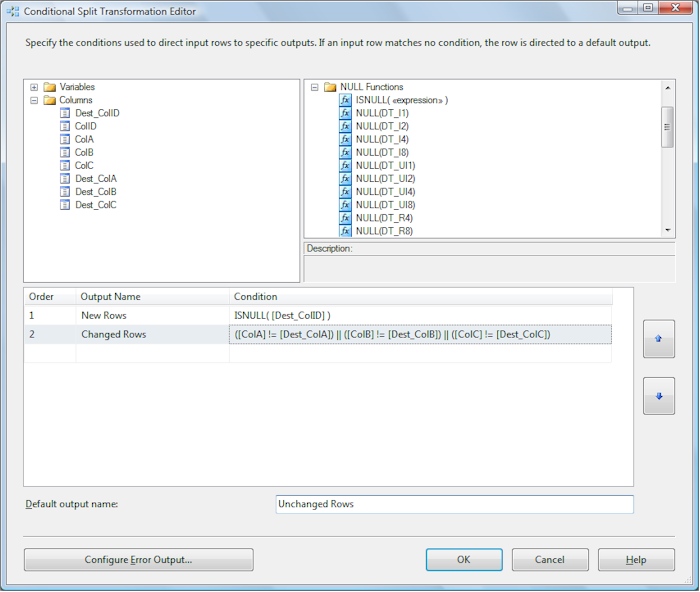
Change the “Default output name” from “Conditional Split Default Output” to “Unchanged Rows”:
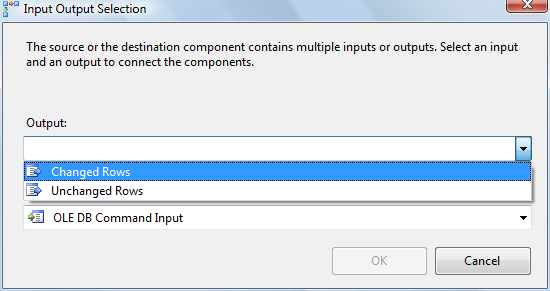
Click the OK button to complete configuration of the Conditional Split transformation. Drag and drop an OLE DB Destination connection adapter and an OLE DB Command transformation onto the Data Flow canvas. Click on the Conditional Split and connect it to the OLE DB Destination. A dialog will display prompting you to select a Conditional Split Output (those outputs you defined in the last step). Select the New Rows output:
Next connect the OLE DB Command transformation to the Conditional Split’s “Changed Rows” output:
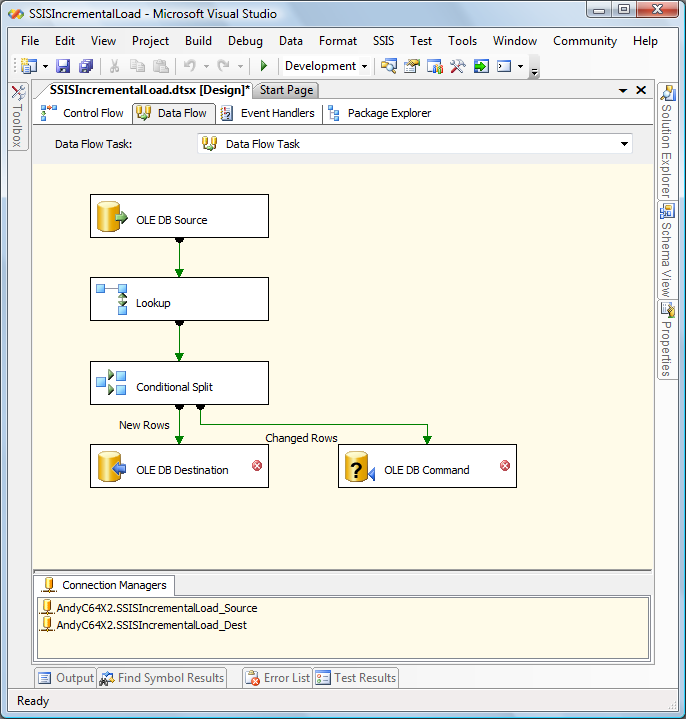
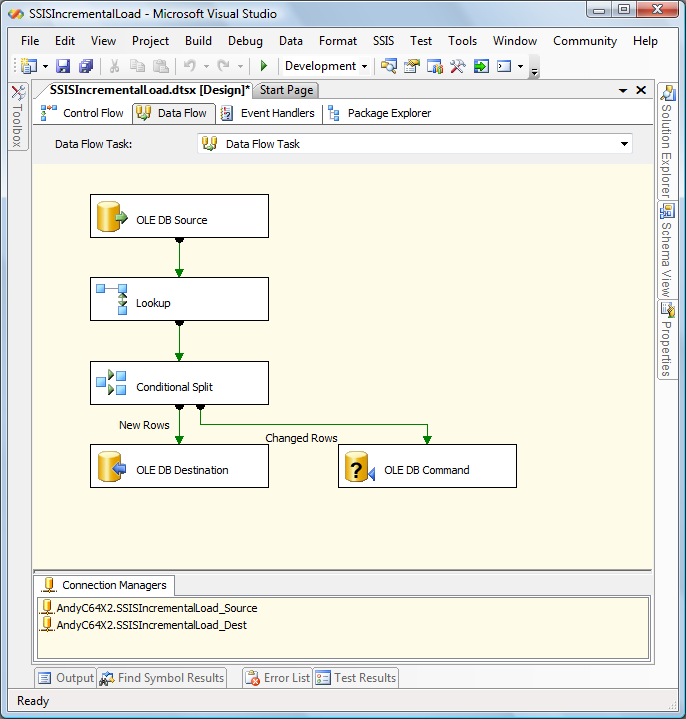
Your Data Flow canvas should appear similar to the following:
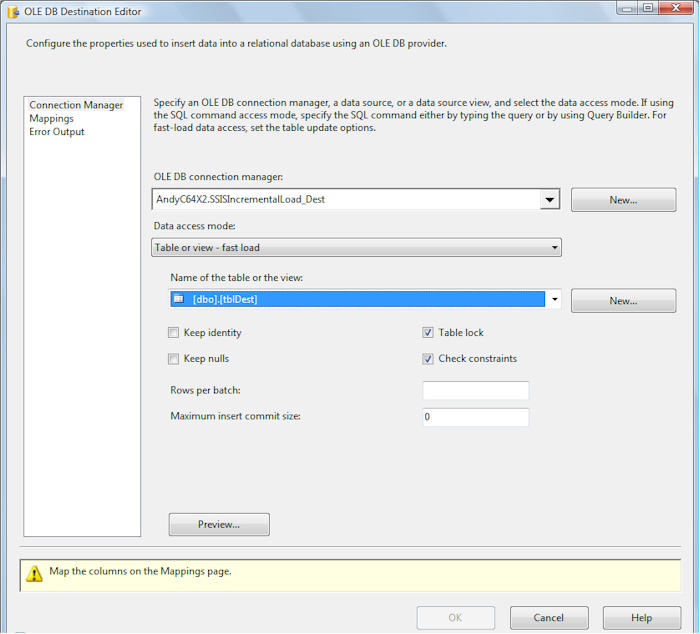
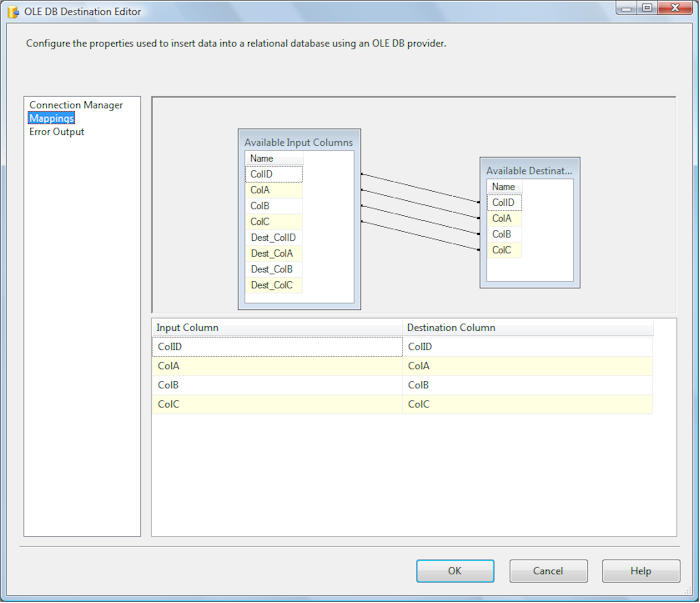
Configure the OLE DB Destination by aiming at the SSISIncrementalLoad_Dest.dbo.tblDest table:
Click the Mappings item in the list to the left. Make sure the ColID, ColA, ColB, and ColC source columns are mapped to their matching destination columns (aren’t you glad we prepended “Dest_” to the destination columns?):
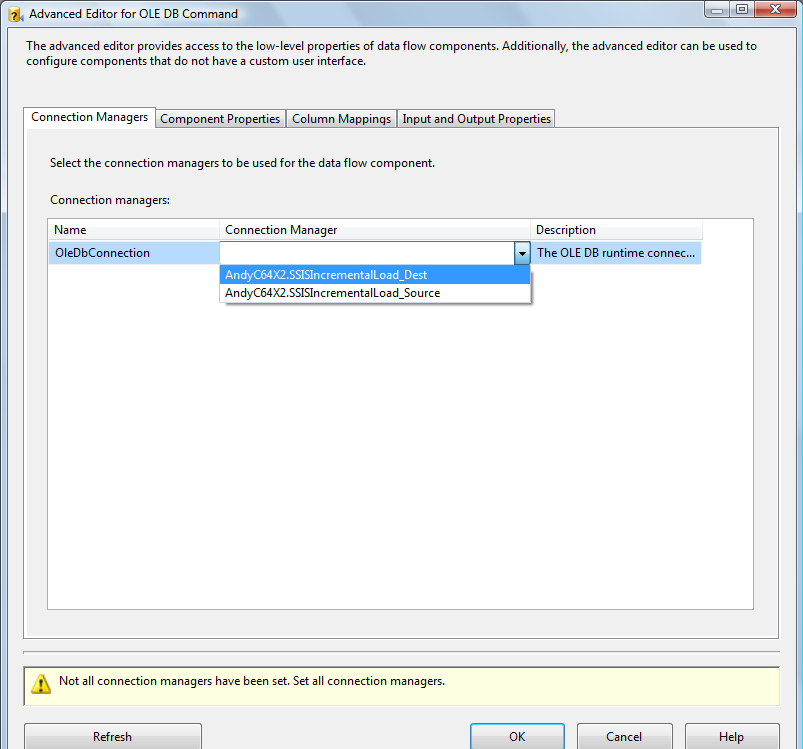
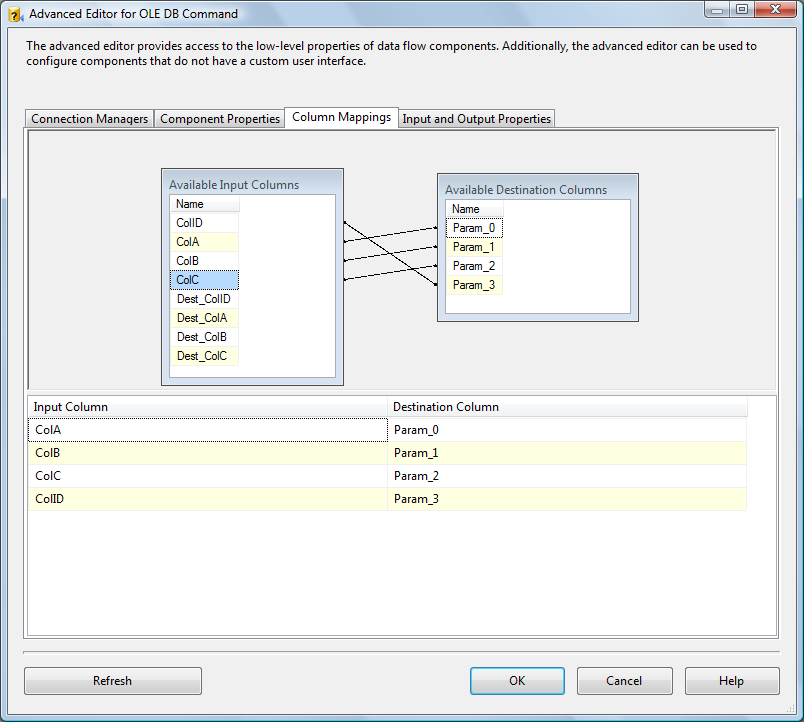
Click the OK button to complete configuring the OLE DB Destination connection adapter. Double-click the OLE DB Command to open the “Advanced Editor for OLE DB Command” dialog. Set the Connection Manager column to your SSISIncrementalLoad_Dest connection manager:
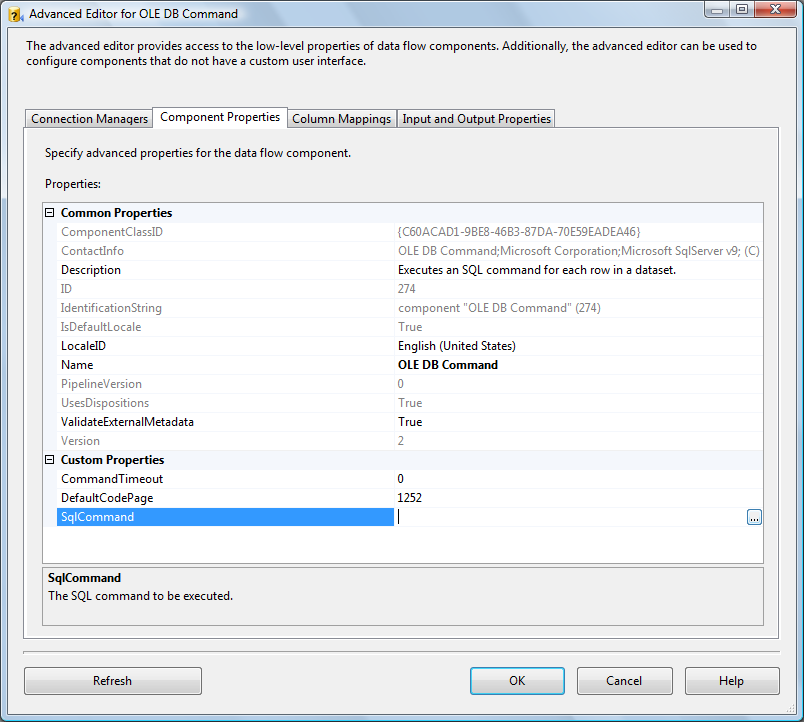
Click on the “Component Properties” tab. Click the elipsis (button with “…”) beside the SQLCommand property:
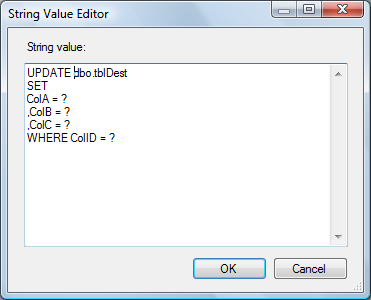
The String Value Editor displays. Enter the following parameterized T-SQL statement into the String Value textbox: UPDATE dbo.tblDest
The question marks in the previous parameterized T-SQL statement map by ordinal to columns named “Param_0” through “Param_3”. Map them as shown below – effectively altering the UPDATE statement for each row to read: UPDATE SSISIncrementalLoad_Dest.dbo.tblDest Note the query is executed on a row-by-row basis. For performance with large amounts of data, you will want to employ set-based updates instead.
Click the OK button when mapping is completed. Your Data Flow canvas should look like that pictured below:
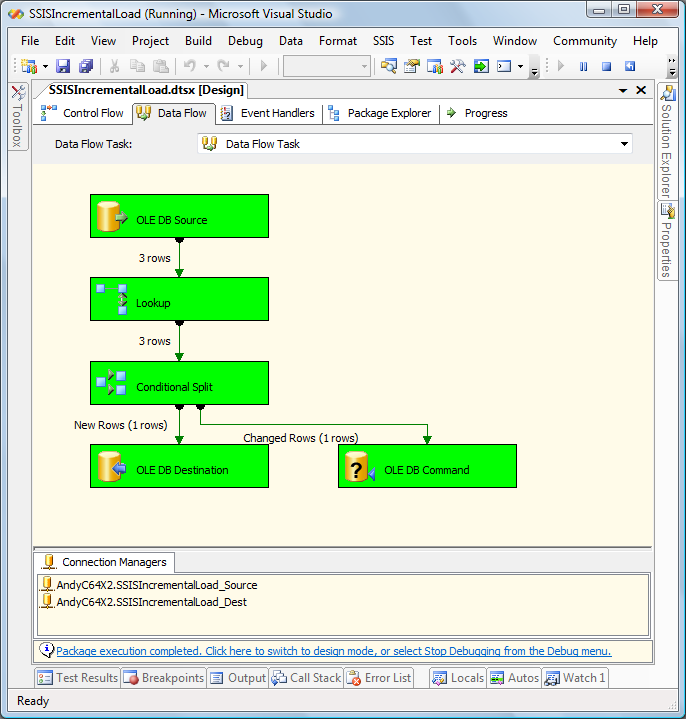
If you execute the package with debugging (press F5), the package should succeed and appear as shown here:
Note one row takes the “New Rows” output from the Conditional Split, and one row takes the “Changed Rows” output from the Conditional Split transformation. Although not visible, our third source row doesn’t change, and would be sent to the “Unchanged Rows” output – which is simply the default Conditional Split output renamed. Any row that doesn’t meet any of the predefined conditions in the Conditional Split is sent to the default output. That’s all! Congratulations – you’ve built an incremental database load! [:)] Check out the Stairway to Incremental Loads at SQL Server Central for more information! (Free registration required) :{> Andy Learn more:
|

Andy, maybe you are interested in taking a look at the TableDifference component I published at http://www.sqlbi.eu.
It is an all-in-one and completely free SSIS component that handles these kind of situations without the need to cache data in the Lookup. Lookups are nice but – in real situaton – they may shortly lead to out of memory situations (think at a hundred million rows table… it simply cannot be cached in memory).
Beware that – for huge table comparison – you will need both TableDifference AND the FlowSync component that you can find at the same site.
I’ll be glad to hear your comments about it.
Alberto
Thanks Alberto! Checking it out now.
:{> Andy
Thank you greatly Andy. This couldn’t have come at a better time as I just started using Integration Services for the first time on Friday to handle eight different data loads (all for a single client). Four of the data loads are straight appends, but the other four are incremental.
This approach is vastly superior to loading the incremental data into a temporary table and then processing it against the destination table. In fact, it proved to be more efficient than both set-based insert/updates or a cursor-based approach. Yes, I tested both approaches prior to implementing yours. Your approach was faster than the set-based insert/updates even though I tested it across the WAN which suprised me greatly.
I also created a script to assist with the creation of the Conditional Split "Changed Rows" condition which follows (be sure your results aren’t being truncated when you have a table with many columns):
— BEGIN SCRIPT —
DECLARE @Filter varchar(max)
SET @Filter = ”
— ((ISNULL(<ColumnName>)?"":<ColumnName>)!=(ISNULL(Dest_<ColumnName>)?"":Dest_<ColumnName>)) ||
SELECT @Filter = @Filter + ‘((ISNULL(‘ + c.[name] + ‘)?"":’ + c.[name] + ‘)!=(ISNULL(Dest_’ + c.[name] + ‘)?"":Dest_’ + c.[name] + ‘)) || ‘
FROM sys.tables t
INNER JOIN sys.columns c
ON t.[object_id] = c.[object_id]
WHERE SCHEMA_NAME( t.[schema_id] ) = ‘GroupHealth’
AND t.[name] = ‘ConsumerDetail’
AND c.[is_identity] = 0
AND c.[is_rowguidcol] = 0
ORDER BY
c.[column_id]
SET @Filter = LEFT( @Filter, LEN( @Filter ) – 2 )
SELECT @Filter
— END SCRIPT —
Again, thanks greatly. I now have 2 SSIS books on there way to me. I am eager to learn as much as I can.
Hello,Andy!Thanks a lot for your incremental process!I’m doing SSIS project!
Thanks this worked a treat for my SSIS project.
Hi David, Bill, and David,
Thanks for the feedback!
:{> Andy
Hi Andy !! Great work… I was scared because of this Incremental load… and you saved my weekend… now I can enjoy it …. 🙂
Anyone had a problem with the insert and update commands locking each other out?
Didn’t happen at first but does now. Update gets blocked by the insert and it just hangs.
Steve
Thanks Saul!
Steve, are you sure there’s not something more happening on the server that’s causing this?
If this is repeatable, please provide more information and I’ll be happy to take a look at it.
SQL Server does a fair job of detecting and managing deadlocks when they occur. I haven’t personally seen SQL Server "hang" since 1998 – and then it was due to a failing I/O controller.
:{> Andy
Hi,Andy! I have a same problem with Steve,it is block. When bulk insert and update happen,Update gets blocked by the insert and it just hangs!Insert’s wait type is ASYNC_NETWORK_IO.
Thx 4 the trick with Fail -> Left Join ! I was thinking how to do it whole day :o)
Steve,
This most certainly can be the case with larger datasets. In my case, I ran into this issue with large FACT table loads. Either consider dumping the contents of the insert into a temp table or SSIS RAW datafile and complete the insert in a separate dataflow task or modify the isolationlevel of the package. Be warned, make sure you research the IsolationLevel property thoroughly before making such a change.
What happens when a field is NULL in the destination or source when determining changed rows? Don’t we need special checks to ensure if a destination field is NULL the source should also be? Thus a change has occured and the record should be updated?
Hi Michael,
Excellent question! This post was intended to cover the principles of Incremental Loads, and not as a demonstration of production-ready code. </CheesyExcuse>
There are a couple approaches to handling NULLs in the source or destination, each with advantages and disadvantages. In my opinion, the chief consideration is data integrity and the next-to-chief consideration is metadata integrity.
A good NULL trap can be tricky because NULL == NULL should never evaluate to True. I know NULL == NULL can evaluate to True with certain settings, but these settings also have side-effects. And then there’s maintenance to consider… basically, there’s no free lunch.
A relatively straightforward method involves identifying a value for the field that the field will never contain (i.e. -1, "(empty)", or even the string "NULL") and using that value as a substitute for NULL. In the SSIS expression language you can write a change-detection expression like:
(ISNULL(Dest_ColA) ? -1 : Dest_ColA) != (ISNULL(ColA) ? -1 : ColA)
But again, if ColA is ever -1 this will evaluate as a change and fire an update. Why does this matter? Some systems include "number of updated rows" as a validation metric.
:{> Andy
Hi Andy,
Thanks for this great article!
Do you have any hints for implementing your design with an Oracle Source. I am attempting to incrementally update from a table with 7 million rows with ~50 fields. The Lookup Task failed when I attempted to use it like you described above due to a Duplicate Key error…cache is full. I googled this and found an article suggesting enabling restrictions and enabling smaller cache amounts. However it is now extremely slow. Do you have any experience/advice on tweaking the lookup task for my environment?
Is there value in attempting to port this solution to an Oracle to SQL environment?
Is there a way to speed things up/replace the lookup task by using a SQL Execution Task which calls a left outer join?
Is there major difference\impact in having multiple primary keys?
Thanks Again
Hi AndY looks great and work also great but if there are more records to update than it just hangs while doing insert and update so what should i do ..is there any workaround by which we can avoid hanging od SSIS pacage. Please Suggest
Thanks
Jigu
Hi Bill and Jigu,
Although I mention set-based updates here I did not demonstrate the principle because I felt the post was already too long – my apologies.
I have since written more on Design Patterns. Part 3 of my series on ETL Instrumentnation (http://sqlblog.com/blogs/andy_leonard/archive/2007/11/18/ssis-design-pattern-etl-instrumentation-part-3.aspx#SetBasedUpdates) demonstrates set-based updates.
I need to dedicate a post to set-based updates.
:{> Andy
Hi Andy
Thanks you did great help to understand data update through SSIS
package
Hi Andy,
I have a hard time following your instructions. Can you send me your sample project
Thank You
Kenneth
aspken@msn.com
Hi Kenneth,
Sorry to hear you’re having a hard time with my instructions.
One of the last instructions is a link at the bottom of the page called "Get the code". It points to this URL: http://andyleonardconsulting.com/dnn/Demos/IncrementalLoads/tabid/94/Default.aspx.
Hope this helps,
Andy
Not sure posted same question few places….May be you gurus can explain
In SSIS Fuzzy grouping objects creates some temp tables and does the Fuzzy logic. I ran the trace to see how it does in one cursor it is taking very long time to process 150000 records. Same executes fine in any other test environments. The cursor is simple and I can post if needed. Any thoughts ?
I have a similar package I am trying to create and this was a big help. The new rows write properly however I am getting an error on the changed rows because the SQL table i am writing to has an auto incremented identity spec column. The changes won’t write to the SQL table. If I uncheck "keep identity" it writes new rows instead of updating existing. What am I missing?
Thanks a lot of Andy!! Very Helpful!
Hi Andy..
Thats the good alternative for slowly changing dimention…!!
Welll done…
What if the increamental is based on more than one columns…?
And further to increase the complications, if any of the column
included in the look up condition changes as well….?
Last one…wht if the row is deleted from source….?
it looks like your package handles new and updated rows.
I don’t see the code handling the deleted rows in source (asume that there is)
Here is my two cents.
in your lookup, you can split out the match and non-match rows.
non match means new record and you can do an insert directly after the lookup. you can elimninate the ‘new row’ in your condition in ‘conditional split’
However, overall, your sample package is the best (at far as I have searched) sample on the net ( I love it, honestly).
Keep up the great work and giving out sample package.
Like most people, I do appreciate your efford.
Ken
Hi Ken,
Thanks for your kind words.
I believe you’re referring to functionality new to the SSIS 2008 Lookup Transformation – there is no Non-Match Rows output buffer in the SSIS 2005 Lookup Transformation.
:{> Andy
Hi Andy,
Thanks a lot for this article. It proved to be a great help for me.
I was wondering if you can provide some solution to handle deleted rows from source table using lookup. I need this because I have to keep the historical data in the data warehouse.
Thanks in advance,
RVS
ranvijay.sahay@gmail.com
Andy, thanks for your help and effort. This is definitely more elegant than staging over to one database and then doing ExecuteSQLs to execute incremental loads.
And re ranvijay’s question, I would assume that when the row exists in the destination but not the source, the source RowID would show up as null, so you could do that as another split on the conditional.
Hi RVS and Charlie,
RVS, Charlie answered your question before I could get to it! I love this community!
I need to write more on this very topic. New features in SQL Server 2008 change this and make the Deletes as simple as New and Updated rows.
I didn’t mention Deletes in this post because the main focus was to get folks thinking about leveraging the data flow instead of T-SQL-based solutions (Charlie, in regards to your first comment). There’s nothing wrong with T-SQL. But a data flow is built to buffer (or "paginate") rows. It bites off small chunks, acts on them, and then takes another bite. This greatly reduces the need to swap to disk – and we all know the impact of disk I/O on SQL Server performance.
Charlie is correct. The way to do Deletes is to swap the Source and Destinations in the Correlate / Filter stages.
Typically, I stage Deletes and Updates in a staging table near the table to be Deleted / Updated. Immediately after the data flow, I add an Execute SQL Task to perform a correlated (inner joined) update or delete with the target table. I do this because my simplest option inside a data flow is row-based Updates / Deletes using the OLE DB Command transformation. A set-based Update / Delete is a lot faster.
I need to write more about that as well…
:{> Andy
Andy,
Looks like I have some rewriting to do on the next version of the ETL. It’s a good thing I enjoy working in SSIS!
I’m working on building a data warehouse and BI solution for a government customer, and a lot of their 1970’s era upstream data sources don’t have ANY kind of data validation. In fact when we first installed in production we found out that they had some code fields in their data tables with a single quote for data! It played merry hob with our insert statements until we figured out what was happening. Then I got to figure out how to do D-SQL whitelisting with VB scripting in SSIS 🙂
Of course since its the government we’ll probaby have to wait until 3Q 2010 before we’re allowed to upgrade to SQL 2008. We were all gung ho about VS 2008 (which we were allowed to get) but imagine my chagrin when I found out that I couldn’t use my beloved BI Studio without SQL 2008… 😛 So I’ll be using this for the next version… and possibly the version after that as well. Thanks a bunch!
Me again.
I think I made a mistake. If a row already exists in the destination table and it no longer exists in the source table, I want it deleted (sent to the deletes staging table). However, the lookup limits the row set in memory to items that are already in the source table, so its not really functioning as an outer join. Its perfect for determining inserts and updates, but I need to do something else to do deletes…
I’m going to try adding an additional OLE DB source and point that at the same table the lookup is checking… hmm, maybe try the Merge? I’ll see what happens and let you know.
Actually I think I need a second pass… grrr.
Andy,
Please feel free to combine this with the previous reply.
What I wound up doing was creating a second data flow after the one that split the inserts and updates out. The deletes flow populated a deleted rows staging table with the deleted row id, which then was joined to the ultimate destination table in a delete command in an Execute SQL task. I would up reversing the lookup, but used the same technique by using a conditional split on whether or not the new column from the lookup was null, and if it was, the output went to the "deleted records" path, which populated the staging table.
The reason I want to actually remove the data from the table as opposed to merely marking it as deleted is because the reason a row would disappear would be because it was a bad reference code in the first place. My big datawarehouse ETL adds new reference codes to the reference tables (which it needs to create in the first place because the source reference codes are held in these five gigantic tables which do not lend themselves to generating NV lists) for unmatched codes in the data tables (remember there’s no validation at the source).
When the reconciliation stick finally gets swung and the customer replaces the junk code it disappears from my ETL and I remove it from my table. It is different from a code that gets obsoleted; there’s a reason to track those, but garbage just needs to be thrown out.
Thanks again, I would have been very annoyed with myself if I wound up doing row-based IUDs…
Hi Charles,
I wasn’t clear in my earlier response but you figured it out anyway – apologies and kudos. You do need to do the Delete in another Data Flow Task.
Excellent work!
:{> Andy
Andy,
Is there a limit to how many comparisons you can make in the Conditional Split Transformation Editor? I have a table with 20 columns, and I’m trying to do 19 comparisons. It’s telling me that one of the columns doesn’t exist in the input column collection. I can cut the expression and paste it back in and it picks a different column to complain about. Error 0xC0010009… it says the expression cannot be parsed, may contain invalid elements or might not be well formed, and there may also be an out-of-memory error.
I’ve been looking at it for 1/2 an hour and all the columns it is variously complaining about are present in the input column collection, so I suspect it’s a memory error. Should I alias the column names to be shorter (ie the problem is in the text box) or is it a metadata problem? I’m going home now but tomorrow I will see if splitting the staging table into 4 tables and splitting the conditions into 4 outputs (to be recombined later by an execute SQL command into the real staging table) does what I need.
Thanks!
Charlie
Hi Andy and Charles,
I thank you for your comments. I still have a few doubts related to handling Deleted columns. I have created a solution to handle all three cases(add,update and delete). I have taken two OLEDB Source(one with source and data and another with destination table’s data) then I have SORTED them and MERGED them(with FULL OUTER join) and finally used CONDITIONAL SPLIT to filter New, updated and Deleted data and used the OLEDB Command to do the required action. I am getting Deleted rows by using full outer join.
I am getting expected result with this solution but I think this is not performance efficient as it is using sort, merge etc. I wanted to use Lookup as suggested by Andy. But the solution which you both have given is not fully clear to me. Will it be possible for you to send me a sketch of the proposed solution or explain it a bit in detail?
Charles, regarding no. of comparisons, I don’t think it is limited to 19 or 20 because I have used more than 35 comparisons and that is working fine. Please check if you have checked for null columns correctly.
Thanks once again,
RVS
(ranvijay.sahay@gmail.com)
Doh! Thanks Ranvijay.
Actually what was happening was that since the comparison expression was so long I moved it into WordPad to type it and then copy/pasted into the rather annoyingly non-resizable condition field in the conditional split transformation editor. It turns out it doesn’t like that. Maybe there were invisible control characters in the string, so I needed to just bite the bullet and type in the textbox. It works fine now.
It would be nice to have a text visualizer for that field.
Thanks!
This was the excellent article and Andy illustration style is great.
Thank you
Great tutorial! I’m new to SSIS and I worked through it without a hitch.
Thanks!!!
Hellow,
Many thanks for the step by step guide.
It’s nice to find a way to get your changed and new records in 2 separate outputs. But how who you get the deleted records? The only solution i found is to lookup every PK in the source db table and check if it still excists. If it does it will set the deleted_flag to 1. Do you have any idea to implement the deleted records into your solution? Mine is in a separete dataflow.
Greetings
Great article! I originally used sort, merge join (with left outer join) and conditional split transforms to perform incremental load. Unfortunately it did not work as expected. Your article has simplified my design and it is now working perfectly. Thanks for sharing. 🙂
Dear Andy
your solution is great but i have problem. the dimensions are not getting populated with the default data. does this work on the excel source because i have an excel source.
Hiya,
Just read the article, confirms my approach to incremental loading on a series of smallish facts.
I have used the "slowly changing dimension" element in the past to facilitate the same outcome, ie not using type2s (despite being a fact) – but it is much slower.
RVA, re: "I am getting expected result with this solution but I think this is not performance efficient as it is using sort, merge etc"; if the sort(s) are the main problem, you can do the sort on the database and tell SSIS that the set is sorted to avoid using two sort dataflow tasks – not sure if that will give you sufficient gains? The Merge join, as you say, will still be not great within SSIS.
Lastly – has anyone any experience of duplicated KEYS in the source table, that do not (yet) exist in the destination?
I am performing bulk-inserts after the update/insert evaluation. I have a minor concern that if I have a key in the source data, that the FIRST record will correctly INSERT, does the lookup then add this key to memory, so that when the second key arrives it knows to update?
Because, although I do not constrain the destination table, it will cause problems within the data (mini carteseans – *shudder*).
Do I need to be aware of any settings or the like? I am about to do a test-case now – and see what happens…
Hi Andy,
I want to load data incrementally from source (MySQL 5.2) to SQL Server 2008, using SSIS 2008, based on modified date. Somehow I am not able do it as MySQL doesn’t support parameters. Need some help on this.
-regards, mandar
Thank you andy for this tutorial. I am using SSIS 2008, the Lookup task interface has changed a little bit, when you click on edit on the lookup task, the opening screen is layed out differently.
In my source ID 3 Record has duplicated KEYS so i want first record Insert and Secode Record should be update in Destination table trough SSIS
Can any one help me to resovle this problem.
When I use SCD 2 type when it read record in target the id 3 record is not avlable in target so it’s treat for insert for second record also same.
So that record insert two time I don’t want like that I want to first record insert and scoend record of ID 3 Update.
So any way of resolve this problem .
ID Name Date
1 Kiran 1/1/2010 12:00:00 AM
3 Rama 1/2/2010 12:00:00 AM
2 Dubai 1/2/2010 12:00:00 AM
3 Ramkumar 1/2/2010 12:00:00 AM
I need to incrementally load data from Sybase to SQL. There will be several hundred million rows. Will this approach work OK with this scenario?
Hi Craig,
Maybe, but most likely not. This is one design pattern you can start with. I would test this, tweak it, and optimize like crazy to get as much performance out of your server as possible.
:{> Andy
Hy there from Portugal,
Andy, i am a starter in SSIS and i found this article very useful and straightforward in explanation with text and images…
Thanks a lot!!
Cheers
Hi Andy
I amended your script to deal with different datatypes (saves a lot of debugging in the Conditional Split Transformation Editor):
/*
This script assists with the creation of the Conditional Split “Changed Rows” condition
— be sure your results aren’t being truncated when you have a table with many columns
*/
— BEGIN SCRIPT —
USE master
GO
DECLARE @Filter varchar(max)
SET @Filter = ”
SELECT @Filter = @Filter + ‘((ISNULL(‘ + c.[name] + ‘)?’+
CASE WHEN c.system_type_id IN (35,104,167,175,231,239,241) THEN ‘””‘
WHEN c.system_type_id IN (58,61) THEN ‘(DT_DBTIMESTAMP)”1900-01-01″‘
ELSE ‘0’ END
+ ‘:’ + c.[name] + ‘)!=(ISNULL(Dest_’ + c.[name] + ‘)?’ +
CASE WHEN c.system_type_id IN (35,104,167,175,231,239,241) THEN ‘””‘
WHEN c.system_type_id IN (58,61) THEN ‘(DT_DBTIMESTAMP)”1900-01-01″‘
ELSE ‘0’ END
+’:Dest_’ + c.[name] + ‘)) || ‘
FROM sys.tables t
INNER JOIN sys.columns c
ON t.[object_id] = c.[object_id]
WHERE SCHEMA_NAME( t.[schema_id] ) = ‘dbo’
AND t.[name] = ‘DimUPRTable’
AND c.[is_identity] = 0
AND c.[is_rowguidcol] = 0
ORDER BY
c.[column_id]
SET @Filter = LEFT(@Filter, (LEN(@Filter) – 2))
SELECT @Filter
–SELECT
— c.*
–FROM
— sys.tables t
–JOIN
— sys.columns c
— ON t.[object_id] = c.[object_id]
–WHERE
— SCHEMA_NAME( t.[schema_id] ) = ‘dbo’
–AND t.[name] = ‘DimUPRTable’
–AND c.[is_identity] = 0
–AND c.[is_rowguidcol] = 0
–ORDER BY
–c.[column_id]
–SELECT
— schemas.name AS [Schema]
— ,tables.name AS [Table]
— ,columns.name AS [Column]
— ,CASE WHEN columns.system_type_id = 34
— THEN ‘byte[]’
— WHEN columns.system_type_id = 35
— THEN ‘string’
— WHEN columns.system_type_id = 36
— THEN ‘System.Guid’
— WHEN columns.system_type_id = 48
— THEN ‘byte’
— WHEN columns.system_type_id = 52
— THEN ‘short’
— WHEN columns.system_type_id = 56
— THEN ‘int’
— WHEN columns.system_type_id = 58
— THEN ‘System.DateTime’
— WHEN columns.system_type_id = 59
— THEN ‘float’
— WHEN columns.system_type_id = 60
— THEN ‘decimal’
— WHEN columns.system_type_id = 61
— THEN ‘System.DateTime’
— WHEN columns.system_type_id = 62
— THEN ‘double’
— WHEN columns.system_type_id = 98
— THEN ‘object’
— WHEN columns.system_type_id = 99
— THEN ‘string’
— WHEN columns.system_type_id = 104
— THEN ‘bool’
— WHEN columns.system_type_id = 106
— THEN ‘decimal’
— WHEN columns.system_type_id = 108
— THEN ‘decimal’
— WHEN columns.system_type_id = 122
— THEN ‘decimal’
— WHEN columns.system_type_id = 127
— THEN ‘long’
— WHEN columns.system_type_id = 165
— THEN ‘byte[]’
— WHEN columns.system_type_id = 167
— THEN ‘string’
— WHEN columns.system_type_id = 173
— THEN ‘byte[]’
— WHEN columns.system_type_id = 175
— THEN ‘string’
— WHEN columns.system_type_id = 189
— THEN ‘long’
— WHEN columns.system_type_id = 231
— THEN ‘string’
— WHEN columns.system_type_id = 239
— THEN ‘string’
— WHEN columns.system_type_id = 241
— THEN ‘string’
— WHEN columns.system_type_id = 241
— THEN ‘string’
— END AS [Type]
— ,columns.is_nullable AS [Nullable]
–FROM
— sys.tables tables
–INNER JOIN
— sys.schemas schemas
–ON (tables.schema_id = schemas.schema_id )
–INNER JOIN
— sys.columns columns
–ON (columns.object_id = tables.object_id)
–WHERE
— tables.name <> ‘sysdiagrams’
— AND tables.name <> ‘dtproperties’
–ORDER BY
— [Schema]
— ,[Table]
— ,[Column]
— ,[Type]
Using T-SQL to do change detection.
I would not use a join to detect change because in the where clause you need to handle NULL values. For example if ColA in Source is NULL it doesn’t matter what ColA is in the destination, the where clause will return false and not detect the change.
To get around this I use a union to detect change. Here is an example.
select ColId, ColA, ColB, ColC from Source
union
select ColId, ColA, ColB, ColC from Dest
This returns a distinct set of rows, including handling NULL values. All that is left is to determine if the ColId appears more than once in the set.
select ColId from (
select ColId, ColA, ColB, ColC from Source
union
select ColId, ColA, ColB, ColC from Dest
) x
group by ColId
having count(*) > 1
Now I have a list of keys which changed. I can take this list and sort it to use in a merge join in SSIS or I can use it as a subquery to join back to the Source table. See below.
select ColId, ColA, ColB, ColC from Source s
inner join (
select ColId from (
select ColId, ColA, ColB, ColC from Source
union
select ColId, ColA, ColB, ColC from Dest
) x
group by ColId
having count(*) > 1
) y
on s.ColId = y.ColId
Thanks for the good explanation and screenshots. I found this website to be extremly helpful and supportive.
Please let me know if I can learn something more from you and rest of the guys visiting this website, so that we can become better in SSIS and SQL server 2005 or 2008.
Please provide us similar articles so that we can through them and practice.
Thanks again Andy.
Long Live Andy 🙂
This is excellent Article ! Great job
Thank you very very much. No where on the net I found it explained in so detail and clear. Thanks again
My requirement is
Update: if records exist in both the table compare them, and update value in destination table if value is different.
Insert: if record doesn’t exist in destination table, add new record in destination table.
Delete: if record exist in destination table but not in source table, delete record from destination table.
The above code, perform only Insert and Update, however, it doesnt Delete data from destination table which has been deleted from Source data.
I would not like to perform Truncate\Delete ALL data from destination table.
Please let me know how shall i do this.
Basically, it should perform Update, Insert, Delete in one single package (task)
Probably not the most common scenario, but if your source and destinations are coming from sql server could you just select checksum(*) as a column from your source and destination tables and test it to determine if the row has been updated? I would think it would be a pretty safe alternative when you have a lot of columns.
Or has anyone created a hashing formula in an expression? (or would that be too slow to consider?)
The following new feature of 2008 R2 seems does the same http://technet.microsoft.com/en-us/library/bb510625.aspx.
Merge may be able to handle this, but if you start working with millions of rows, it tends not to perform too well. For smaller data sets, it’s pretty effective, but I’ve seen that command sit for a while as Merge tries to calculate the updates/inserts.
Hi Andy,
Its great article. Very well explained. But I was wondering I am having around 20-30 tables in mysql and I have to use SSIS package for moving data of this tables to sql server. Some of the tables has 40-50 million records. I have to do this load very frequently (might be daily), is this best approach for it or if you can suggest some better approach.
Change Detection is a topic of many design patterns. Here I used a rather brute-force method for detecting updates, mainly to demonstrate the concept. There are more methods for detecting changed rows and I hope to blog about some soon.
Thanks for the comments!
:{>
This works great!
Now the issue is, I have more than 100 tables which need an incremental load..
Do i have to build 100 packages? or is there an easy way out?
Please Help..
i just want to load based on the date ie if our table have date column we will capture that maximum date based on the loading if again running our package it allows which records have date greater than already capturing date. Allow this records only by the we can get only new records to target.
can you please some idea to achive this?
Thanks & Regards,
Thirunavukkarasu P
Hi Kal,
i have actually the same problem. Maybe you can use the Slowly Changing Dimension Tool. This generates Updaten and insert command for you.
Hi Andy!
Thanks a lot for that topic.
I’m starting to use SSIS and i have some doubts:
a) If my Destionation Database is null, i got error. Don’t insert the rows.
b) What can i do to delete rows on destination database who not exists on source database?
c)If i have come source column with null, don’t update the destination. But that i understant why a i see your sugest:
(ISNULL(Dest_ColA) ? -1 : Dest_ColA) != (ISNULL(ColA) ? -1 : ColA)
Thank u a lot…nice explanation
Could you please explain further….
"Note the query is executed on a row-by-row basis. For performance with large amounts of data, you will want to employ set-based updates instead."
Thank you
Experts, i have a question.I’m working on loading a Very large table having existing data of the order of 150 million records which will keep on growing by adding 1 million records on a daily basis.Few days back the ETL started failing even after running for 24 hrs.In the DFT, we have source query pulling 1 million records which is LOOKed UP against the Destination table having 150 million records to check for new records.It is failing as the LOOKUP cannot hold data for 150 million records.i have tried changing the LOOKUP to Merge Join without success.Can you please suggest alternative designs to load the data in the large table successfully.Moreover, there is no way i can reduce the size of destination table.i already have indexes on all required columns.Hope i’m clear in explaining the scenario.
Hi D,
You can limit the number of rows used by the Lookup by using a SQL query as the Lookup source instead of the entire table.
Hope this helps,
Andy
Thanks for the reply Andy.I have already mentioned that it’s not possible for me to actually reduce the size of the LOOKUP Query since i need to check existing rows which can be anywhere in the table.Something came to my mind just now on which i would like expert comments.I’m thinking about splitting the target table into parts with sql query and use it to join with source sql query to find possible newer records which would be joined with the various parts of the destination table one by one to get to the actual new records.Will try that at work tomorrow, just came to mind now.Would appreciate a lot if you can suggest any better alternative.
Hi D,
I recommend identifying the rows in the large table before you reach the lookup, and staging the data you need to return from the lookup – along with the lookup-matching criteria – in another table. Truncate this table prior to loading it. Populate it. Then use it for the lookup operation. Kimball refers to this a "key staging".
Hope this helps,
:{>
Hi andy,
I tried this article in BIDS SSIS 2008 R2
but every time it had to to update it wont do any update instead it inserts a new row. As given in above example when ColID =1 it needs to update ColA but instead it inserts new colA with same Colid=1 so it has now two rows with Colid=1 one with cola = b and other with cola =c:( any idea where i went wrong….i followed the same steps which have been given by you.
Thanks,
dilip
Hi Andy, Very nice article. I had another question though, how do you handle data deletes. I see that the new records are inserted and changed ones are updated. What about the records that were deleted?
Thanks
Neha
Hi Andy, Awesome posts.
I have one question not sure if this is the right place. I am working on a data warehouse load that has comprises of multiple SSIS packages and my challenge is to make it rerunnable. Each package calls a stored procedure which is rerunnable i am trying to add something like a Batchid to each run. any ideas on how this should be approached?
thanks!!!
Hi Jessica,
I wrote a post recently about designing an SSIS Framework. It can help. There are other potential gotchas with DW loads, so please hit the email link in the upper right of this page. We’ll. Probably do more good taking this offline.
:{>
I am the beginner for SSIS packages . It is very useful
Thanks a lot
Hi Andy,
I followed the article published today – level 4 http://www.sqlservercentral.com/articles/Stairway+Series/76390/.
I know you are going to publish article to take care of deletes as well. But I need to implement this in my project by this week. Do you have deletes article handy? Also, I neeed to work with 40 + tables and the SSIS package should refresh the destination database every 8 hours. How do I manage 40+ tables and data resfresh every 8 hours. Can you please suggest me better solution to achieve this?
Hi Indy,
Please email me at andy.leonard@gmail.com.
Thanks,
Andy
This OleDB command will be slow for lakh number of records..
By loading the data into stage table and update it outside the dataflow using execute sql task is one option….
Any other option is available to improve the performance of the package.
Hi Amu,
You are correct and thank you for pointing this out. I have written another series about SSIS Incremental Loads for SQLServerCentral.com. I cover your suggestion in Step 4 of the Stairway to Integration Services (http://www.sqlservercentral.com/articles/Stairway+Series/76390/).
:{>
Sorry i mean
does it able to handel the deleted rows ( not columns sorry for that ) in source table it shouls effect the destination to
by the way i am using sorce as oracle data base
Hi Mali,
Check out Step 5 of the Stairway to Integration Services – it talks about Deletes: http://www.sqlservercentral.com/articles/Integration+Services+(SSIS)/76395/
Hope this helps,
Andy
Hi Andy,
if a cloumn has null values
condition split saying "The expression results must be Boolean for a Conditional Split"
my error is
[Conditional Split [127]] Error: The expression "(STATUS != L_STATUS) || (ORDER != L_ORDER)"on "output "Update" (167)" evaluated to NULL, but the "component "Conditional Split" (127)" requires a Boolean results. Modify the error row disposition on the output to treat this result as False (Ignore Failure) or to redirect this row to the error output (Redirect Row). The expression results must be Boolean for a Conditional Split. A NULL expression result is an error.
Hi Andy,
Thanks a lot for that,
right now i am facing a problem that my records r some millions
so its is geeting error as out of memory some thing so on
is there any suggesion on that
Thanks
Malli
I got it
anyway thanks for your post which u have posted recentelly.
Thanks,
Reddy
Hi Andy
The error is
Error: The system reports 89 percent memory load. There are 3477643264 bytes of physical memory with 357049128 bytes free. There are 2147352579 bytes of virtual memory with 97837956 bytes free. The paging file has 5452554249 bytes with 1323617112 bytes free.
Hi Andy
The error is
Error: The system reports 89 percent memory load. There are 3477643264 bytes of physical memory with 357049128 bytes free. There are 2147352579 bytes of virtual memory with 97837956 bytes free. The paging file has 5452554249 bytes with 1323617112 bytes free.
I am attempting to incrementally update from a table with 170 million rows with 78 fields. The Lookup Task failed when I attempted to use it like you described above due to a Duplicate Key error…cache is full. However it is now extremely slow. Do you have any dvice on tweaking the lookup task for my environment?
my source is from Oracle
Is there a way to speed things up/replace the lookup task by using a SQL Execution Task which calls a left outer join?
Thanks Again
You should consider using a query in the Lookup Transformation and not selecting the table name from a dropdown. Selecting the table name essentially attempts to load the entire table into RAM before the data flow executes. Limiting the rows and columns returned will shrink the data volume returned.
You can also look into key-staging. There’s mention of it here (http://msdn.microsoft.com/en-us/library/cc671624.aspx) in the section on Targeted Staging.
Another pattern to consider is Range-based lookups (http://blogs.msdn.com/b/mattm/archive/2008/11/25/lookup-pattern-range-lookups.aspx).
Hope this helps,
Andy
Hi Andy,
This article has been veryuseful as I have built a package that almost works… 😉
It actually works for 4 out of 5 tables. The 5th table actually has a 5 field combined primary key.
So in the Conditional Split
–New rows, I put the following:
Isnull(Dest_field1) && Isnull(Dest_field2) && Isnull(Dest_field3) && Isnull(Dest_field4) && Isnull(Dest_field5)
which are the 5 fields that make the primary key.
and in the — Changed Rows, I put the following
(Field1 == Dest_field1) && (Field2 == Dest_field2) && (Field3 == Dest_field3) && (Field4 == Dest_field4) && (Field5 == Dest_field5) && (TimeStamp != Dest_TimeStamp)
which to me is just simply logical.
The problem I’m having is that I get a insert Primary key violation… for which I’m not too sure how to troubleshoot since I only know the basics.
What do you think I’m doing wrong?
Hi John,
You want to use the Lookup Transformation to manage mapping your primary key fields. Remember, the Columns tab of the Lookup is akin to setting the JOIN ON clause. If you were joining this table in T-SQL, you would include all five fields.
Hope this helps,
Andy
Hi again Andy,
Thank you for the pointer… It actually helped me understand and fix my problem.
I had all columns chosen for the join in the Lookup transformation. By just joining the keys and it helped me understand the conditional split conditions.
All I need now is to learn more about debugging and error handling which is still a big blur for me…
Thanks again! Great blog! 🙂
Thank you very much AndyLeonard, this is very helpful.
Many thanks
Hi Andy,
Could you please advise how to do incremental load for 300+ tables, as it would be difficult to create dataflow for all tables and I have the requirement to use SSIS along with logging of how many records are inserted/updated. Could please help me out on the approach to be taken through SSIS.
Thanks and Regards,
Samit Shah
Hi Sanity,
A couple options come to mind. 1. Use. Net to generate and save the packages. 2. Use BIML ( http://agilebi.com/blog/tag/biml/)
Hope this helps,
Andy
Hi Andy
Thanks for the help. I was able to create the packages using BIMLScript.
Thanks and Regards,
Samit Shah
hi andy , great article. However, I have two questions
1. When you detect new rows, you used left out join the source table
to the target table and find all records where columns from right tables are null. That’s fine but what about if source and target tables contains billion records? Is that applicable?
I know the other alternative might be extracting the max(modifiled_date) from the target table and get data from source where date is greater than max(modified_date), what about if there are no such audit columns on the source and target tables?
Thanks
Hui
Hui,
In those cases, you are probably better off using some sort of max(Created/Modified Date) – with an index! If you’re replicating that table, it could potentially be added as a computed column on the replicated side with the index created there. That would let you know what records are new/changed since the last run. Pull those values into some form of staging table and compare against that – it will likely perform better that way than doing a direct join.
thanks peter. do you know any way to add audit columns as a computed column on the replicated side? In my case, our source table did not
contain such audit columns and in order to add that one, seems I need
to write a trigger so that a timestamp will be inserted to each record whenever there is a transaction? Do you have any suggestions?
Hui, that’s where you start running into issues. If you don’t have something in your row that’s tracking Created/Updated Dates, you’ll need to add it and possibly a trigger as well. Created Date is pretty straightforward to default. Updated Date would need an AFTER UPDATE trigger to populate it. I think it could still be done on your replicated side, but in this case, you’re better off adding it to your main source database. You’ll likely want it at some point even if you don’t think you’ll need it.
If the data is strictly INSERT, you can get the max PK value (or some other unique value) and run against that. You have the option of Service Broker as well, but that takes some work and probably more triggers to manage. If you’re on SQL 2008 Enterprise, CDC may be an option.
In our case, we have Created/Updated Dates (some NULL) and were able to create a computed column to show COALESCE(Updated, Created, ”) as WarehouseLoadDate. We could then index that and find just the rows that were new/changed. From there we processed as appropriate.
hi andy
i have a project where i need to load date each time for only 2 month
and every year delete the last month and than reload with the next month. i’m having trouble with that i would be great if you could help me out with some ideas
thanks
jim
Hi andy
Can I replace the you source DB by a Excel file?
Thanks
Eliana
Hi Eliana,
Yep, but there are a limited number of SSIS data types available from Excel (8, if memory serves) and mapping them to SQL Server data types can be "tricky".
:{>
Hi Andy
Yepp I got a lot of headaches when I try to format import excel files to DB using SSIS solutions . Do you know some trickies for that?
Now I’m trying to testing your solution but using 2 tables (1 source and 1 destination table) in the same DB
I’m imported the excel file to mytable_source (tmp) and I made a lookup and split from here to update and insert new records into mytable_dest. But I’m still having issues… Mytable_Source have the same structure like Mytable_Source, even the Increment ID, but I want to use other fields to determine if the records are new or update. But no records are inserted and changed
Any idea?
Hi Eliana,
You may want to take a look at another series of articles I wrote about Incremental Loads. It provides more detail and screenshots. You can find the series at http://www.sqlservercentral.com/stairway/72494/.
Hope this helps,
Andy
Hi Andy,
I’ve an issue and I don’t know what I’m doing wrong!!!
1. I have a SOURCE table with records and an empty DEST table.
2. I want to use 2 fields for a lookup, OrderDate and OrderNo
3. I choose only these in available lookup columns (join) and I used DES_ in the Output alias
4. In the conditional Split I’m using the following contidions
4.1 New Rows –> (OrderDate != DEST_OrderDate && OrderNo != DEST_OrderNo)
4.2 Change Rows –> (OrderDate == DEST_OrderDate && OrderNo == DEST_OrderNo)
but When I ran any new rows has been inserted
what I’m doing wrong?
Thanks
Eliana
Hi Eliana,
You detect new rows by checking for a NULL (using the SSIS IsNull function) on any column returned from the Destination in the Lookup transformation. You use the expression currently in your New Rows detection to detect Changed Rows.
Hope this helps,
:{>
Thanks for the help, it’s working now
Regards,
Eliana
Good job, Eliana!
:{>
Hi Andy,
I hope you can help me with this new issue
Now I have a solution perfectly running separately but. If I want to run all together that is stuck in the validation phase of my second task.
My solution have 3 stages
1. Import excel file to my source table (53647 rows)
2. Insert/update my dest table, from source table (using lookup and conditional split)
3. truncate source table.
First stage is ok
Second is stuck in a SSIS.Pipeline: Validation phase is beginning. showing yellow color in the Data flow but doing nothing.
I setup Delay Validation as a True in each DataFlow but this is ignore I guess.
If I ran each Dataflow separatelly that ran oh and faster
What I have to do to improve it?
Thanks
Eliana
Hello Andy,
Your article has been very helpful.
Thanks,
Sarika
Great Artical…Thanks sir
hi Andy,
You said: You can limit the number of rows used by the Lookup by using a SQL query as the Lookup source instead of the entire table.
Is it possible to dynamically pass a value from the destination table to a where clause in such a query? So I can, for example, fine max(ID) in the destination, and only get rows from the source that are greater than that (meaning only new rows)?
thanks
Hi Ron,
In SSIS 2008, yes you can. The Lookup Query is exposed in the Expressions for the Data Flow containing the lookup transformation.
Hope this helps,
:{>
Hi friends,
in increment loading i have small doubt.please clarify me.
here we are useing oledb command for updateding records.
without useing oledb command is it possible or not to update records.
that time is it possible to use execute sql how to we use in control flow level. i follow same query to write in execute sql task. and mapping paramers variable.i write query in execute sql task like
update table set name=? ,
sal=?
where id=?
and i map parmerts mapping.
but its no updated any record.
i want achive same result useing execute sql task.plese tell me wha steps i need follw.
thanks i does not clear tooo much can you provide the video that would help me lot. thanks thanks thanks in advance
with regards
rohit
rohitsethi123@gmail.com
I recommend you take a look to the Dimension Merge SCD component and the video set from youtube (specially the 6th one)
http://dimensionmergescd.codeplex.com
New to SSIS ? Andy Leonard is the name to remember. Article of July 2007 still getting appreciated & lauded , Updated in sqlservercentral to date.
Thank you very much ANDY for sharing your knowledge.
Andy,
Thank you very much for this contribution. I searched a lot for something like this and none of the things I found, worked like yours. I was trying to import a XML file into a SQL Server 2008 and your example worked just perfectly. Thanks again.
Thank you so much, am a baby in this hence my question, can I use same to do my incremental load on my fact table? what if I don’t want to use the conditional split but just want to insert , update in the destination?
Hi andy .
How can I go for Update and Delete with this SSIS package.
thanks.
Thanks Andy, your article gave me a head on on the job.
Hi Andy,
I am a beginner with ssis packages..currently im working with sql server 2008 database. I have to implement an ssis package which should take data from oracle database to sql db. I have successfully implemented it, but the issue is that it is not checking ‘new data’ in oracle…its just appending all the rows in source table to destination table. so im facing data duplication issue. Could you please help me to solve this? i just wan that, my ssis package should take only ‘new data’ from oracle and insert it to sql.
Thanks in advance,
Hi Gibs,
The scenario you describe is addressed by implementing an Incremental Load design pattern. This very post will solve the issue of duplicated rows appended to the destination table.
You may also want to check out my series at SQL Server Central: Stairway to Integration Services (http://www.sqlservercentral.com/stairway/72494/). In it, I describe the Incremental Load Design Pattern in more detail.
Hope this helps,
Andy
Hi andy,
i need to create one ssis package
in Prodserver i have 200 tables with 6 schemas.
I need to initial load and Incremental load all these 200 tables
using ssis pkg from prod server to sandbox.
shall i need to create 1 pkg for each table for all 200 tables? or
Please help me how i can proceed.
Thanks in advance
venky
Hi Andy,
May be you will help me with my issue. I need to load .xls files, but my files are builed so that i cannot load every column till it’s ending, but i need to stop loading in the specific row.
That means, if i have, for example, columns with 50 rows, there are only 10 rows to be loaded.
How can i stop the loading exactly on the 10th row for each column?
Is that foreach container? conditional split?
Thanks very much
Hi Irit,
One way is to add a Script Component. In .Net, you can count the rows flowing through the buffer and only output rows while the row count is less than or equal to some value.
Hope this helps,
Andy
Andy, the problem that the row number is changing all the time, but i have the blank row after the rows, which have to be loaded, so maybe this can help us to stop the loading till arriving to the blank row?
Hi Irit,
You could use a Script Component to detect the blank row. If the blank row is consistent and the number of rows varies, that’s the approach I would take.
Hope this helps,
Andy
Hi Andy, Excellent article and thanks a million, Sir Andy, this help me a lot, but no all isn’t color Rose, lol. I implementet this project, with my environment; my big problem, I think is the lookup flow. When execute my project, the space size in HardDisc “C:\” disappears, Can you tell me why occurs it?
Excellent post, very clear.
Nice Work
It was very useful post
Very good guidlines
Hi Andy and all,
I have been using your example for developing some packages. For most of them, it is working beautifully. There is just one package which some fields contains NULL look up values. In this case, the ‘changed rows’ condition evalutes to NULL and gives error messages saying the condition should evaluates to a boolean value. I got around it by setting ‘ignore failures’ in the condition split component. Next I found, the update of the changed rows still evaluate to NULL as long as the lookup table contains NULL values in those rows. Can you suggest what I need to do in this case? I hope I explained my issues clearly. If not, please let me know. thank you so much.
Hi Andy,
I sent you a question earlier. Did you get it and can you help? It is urgent as it may be true to everyone who has a question. thank you
Hi Hannah,
I appreciate you reading and commenting on this blog. I try to be responsive to questions from readers but sometimes I’m engaged in my day job and cannot respond as quickly as readers would like. Other times I am partially or completely disconnected from the internet for days or weeks. I recently returned from a trip out of the country, for example, and was offline much of that time. I know authors of many popular blogs and many of them operate in a similar fashion.
I’ve written a series at SQL Server Central called the Stairway to Integration Services (http://www.sqlservercentral.com/stairway/72494/). The fourth article in the series (http://www.sqlservercentral.com/articles/Stairway+Series/76390/) provides a working description of using the SSIS Expression Language IsNull function in a Change Detection expression.
Hope this helps,
Andy
Really very Useful article …. thanks Mr.Andy
Really very Useful article …. thanks Mr.Andy
Will this work for large data sets?
Hi Andy
Really very Useful article. Thanks for the help.
Thank you very much Andy
Hi Andy ,
I followed the same steps given by u , if i update any row in source table it is going as a new row for destination table and not getting updated
clarity on the content is more appreciated.Thanks for making it simple to understand
Thank you for presenting the article in very simple way. It was really to understand .:)
Hi Andy,
great Article. It’s good to see something that was started in 2007 still going 🙂
I am after a simple solution but at the same time it shows itself hard to find. I am looking for slowing changing dimensions/delta type of solution but instead of done per table which is what SSIS is based on I would like to be able to have a configuration table specifying the metadata which will be used by the package. Do you know of any solution which can implement this? would you recommend any?
Cheers,
Gus.
It’d be better if we can use Hashbytes column on Conditional Splitting for ‘Changed Rows’.
Hi Andy,
thanks for your great work.
I just have, hopefully, a simple problem. I have the errorcode -1071607764, which tells me "The expression evaluated to NULL, but a Boolean result is required. Modify the error row disposition on the output to treat this result as False (Ignore Failure) or to redirect this row to the error output (Redirect Row). The expression results must be Boolean for a Conditional Split. A NULL expression result is an error." after the conditional split.
Unfortunately I have no clue at the moment why this error occurs..
Do you may have an idea?
Thanks in advance.
Cheers Tom
Hi Tom,
You’re getting that error because one of the values in a column used in the expression is NULL.
I’ve written a series at SQL Server Central called the Stairway to Integration Services (http://www.sqlservercentral.com/stairway/72494/). The fourth article in the series (http://www.sqlservercentral.com/articles/Stairway+Series/76390/) provides a working description of using the SSIS Expression Language IsNull function in a Change Detection expression.
Hope this helps,
Andy
Hi Tom.
I faced to your same error. To overcome this, I use ISNULL expression to identify those NULL values and change to ‘space’ character to ensure the correct equal expression in Conditional Split.
@andy: is it the same with your solution or do we have other better solution on this issue?
Thanks a lot,
Phong Le Ngoc Ky
Hi Andy,
thank’s a lot for your help 🙂
I’ve found the mistake and my process is working now.
The Stairway to Integration Services is also awesome.
Kind regards
Tom
I have a fact table which has about 27 million records and i am trying to update the fact table so i don’t have to fully process the cube every day. The pattern i am following is using look ups to verify whether it an existing record or a new record. I am using SSIS as the etl tool. I am wondering what would be the best way to handle it. Should i load the Source system key from the fact in a cache look up and then compare or try to follow something else.
Any response or help would be really appreciated.
Very nice article and thank you so much Andy !
Satish Kumar
"insert bulk failed due to a schema change of the target table" while executing Incremental packages in production environment.
Some of the records inserted successfully but in the middle i faced this problem
and when i execute in local everything working fine with all success
"insert bulk failed due to a schema change of the target table" while executing Incremental packages in production environment.
Some of the records inserted successfully but in the middle i faced this problem
and when i execute in local everything working fine with all success
I am loading data from sql server to oracle as incremental load and always data loading into new rows because in the look up tranformation ,data is showing null even data is available in destination table.
Can u pls advice.
Regards,
I faced the same problem as you DBA-HELPER when I deal with Oracle related SSIS. For loading from Oracle to SQL, after changing the lookup from Full Cache to Partial Cache the package executed correctly when new rows or updates are added.
However, the same issue couldn’t be solved when I load data from SQL to Oracle.
Anybody got any insights or did DBA-HELPER solved it? Please help me 🙁
just want to say this incremental load is complete and really useful for me. Thank you!
Hi. I have a QQ. I have the source table in SQL Server Database and the Target Table is in Oracle Database. And I’m dealing with in average 140000 records. Which is the best way to do the incremental load with two different databases used. This is an urgent request. Also, with the date field in SQL Server yyyy-mm-dd and in oracle is dd-MON-yy. How can I use that date field in both for update task in the conditional conflict task.
Cannot believe how useful is this page even in 2016!
how to create query…
Sample table : Transact
Entry Date PartyIdno Catage Credit/Debit Amount
—— ———- ———- ——— ———— ——–
1 02-01-2016 1 Receipt C 8,200
1 02-01-2016 5 Payment D 8,200
2 14-02-2016 1 Sales D 11,200
2 14-02-2016 4 Sales C 6,500
2 14-02-2016 2 Sales C 4,700
Output
——
Entry Date PartyIdno Debit Credit Balance
—– —— ———- —– ——- ———–
SubId SubAmount
—– ———
1 02-01-2016 1 8,200 8,200 Cr
02-01-2016 5 8,200 Dr
2 14-02-2016 1 11,200 3,000 Dr
14-02-2016 4 6,500 Cr
14-02-2016 2 4,700 Cr
SQL Statement :
GLOBALSSS.Open_DB_Connection()
Dim cmd As New Sql Command(“Select T1.ENTRY,COALESCE(T1.PARTYIDNO,T2.PARTYIDNO) AS Colour FROM TRANSACT T1 FULL OUTER JOIN (SELECT PARTYIDNO FROM TRANSACT WHERE ENTRY=1) T2
ON 1 = 0 WHERE T1.PARTYIDNO=1 OR T2.PARTYIDNO<>-1 “, Connection)
Dim da As New SqlDataAdapter(cmd)
Dim dt As New DataTable
da.Fill(dt)
DataGridView1.DataSource = dt
GLOBALSSS.Close_DB_Connection()
HI After this step ”
UPDATE dbo.tblDest
SET
ColA = ?
,ColB = ?
,ColC = ?
WHERE ColID = ? ”
i did not understand. How to set up parameter to param 0 param 02?
do i need to write this code ?
UPDATE SSISIncrementalLoad_Dest.dbo.tblDest
SET
ColA = SSISIncrementalLoad_Source.dbo.ColA
,ColB = SSISIncrementalLoad_Source.dbo.ColB
,ColC = SSISIncrementalLoad_Source.dbo.ColC
WHERE ColID = SSISIncrementalLoad_Source.dbo.ColID
is there any chance.
If source file is deleted, it need to effect on destination file
how can we use condition for that in conditional split,
the above ssis package is gud ( i am working wth it )
but the thing is it cant handle the deleted tables
can u help me with that