
Introduction
In this SSIS Snack, I continue with the package in the last SSIS Snack. The Data Flow Task in the package currently looks like this:
Configure a Conditional Split
Drag a Conditional Split Transformation onto the Data Flow canvas and connect the output of the Lookup (“Correlate”) to it. Open the editor, we’re going to add two outputs: New Rows and Updated Rows.
For New Rows, we recall from our last SSIS Snack the Lookup functions as a Left Outer Join. That means any row in the pipeline that doesn’t have a corresponding row in the destination table will return NULLs for the “Dest_” columns. So we can detect new rows in the pipeline by testing for NULLs after the Lookup:
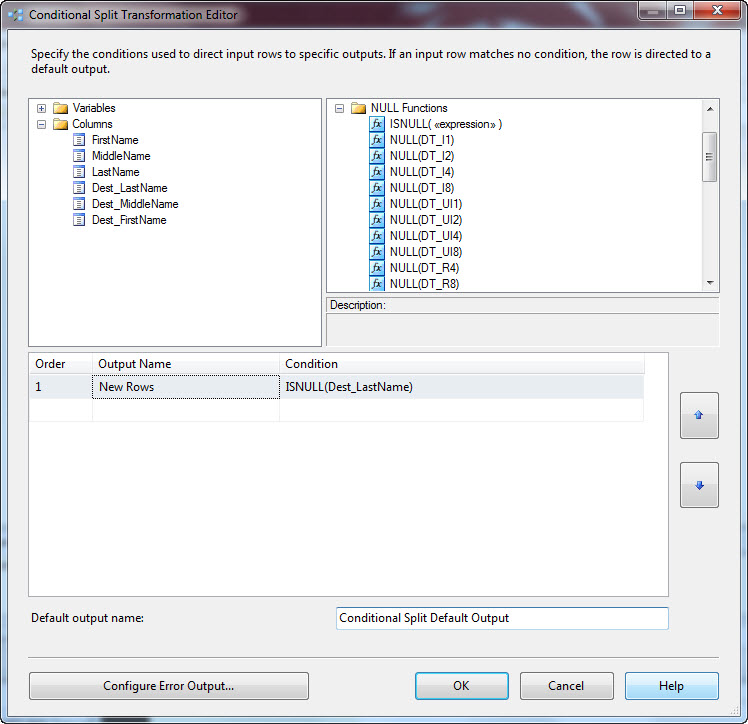
Now, any of the “Dest_” columns will be NULL when there’s no match in the Lookup. I choose the Dest_LastName column.
For Updated Rows, one way to detect changes is to compare the values in each source column with their corresponding value in the destination table (via the lookup). So the first pass at the expression is a comparison between each source and corresponding destination column:
(LastName != Dest_LastName) || (MiddleName != Dest_MiddleName) || (FirstName != Dest_FirstName)
This almost works. The reason it won’t work is MiddleName is NULLable. The expression will fail if one of the values evaluates to a NULL.To make this work I need to trap the NULLs and convert them to some non-NULL value for comparison. So I modify the expression to read:
(LastName != Dest_LastName) || ((IsNull(MiddleName) ? “?^$@” : MiddleName) != (IsNull(Dest_MiddleName) ? “?^$@” : Dest_MiddleName)) || (FirstName != Dest_FirstName)
This is tricky, because I cannot select a non-NULL value that will ever show up in the data. Why? Consider what happens if I select a MiddleName value that exists in the source data where a NULL exists in the destination. In that case, the source middle name evaluates as not NULL and is passed through the comparison. The second value is NULL and is translated by the expression into the very value in the source column – which means the not-equal will not detect the difference and the change detection will fail.
To compensate, I throw all kinds of stuff into the non-NULL comparison value. I use characters I never expect to see in a middle name.
The last step is to configure the default output, which rows that are not new and are not changed will flow to:
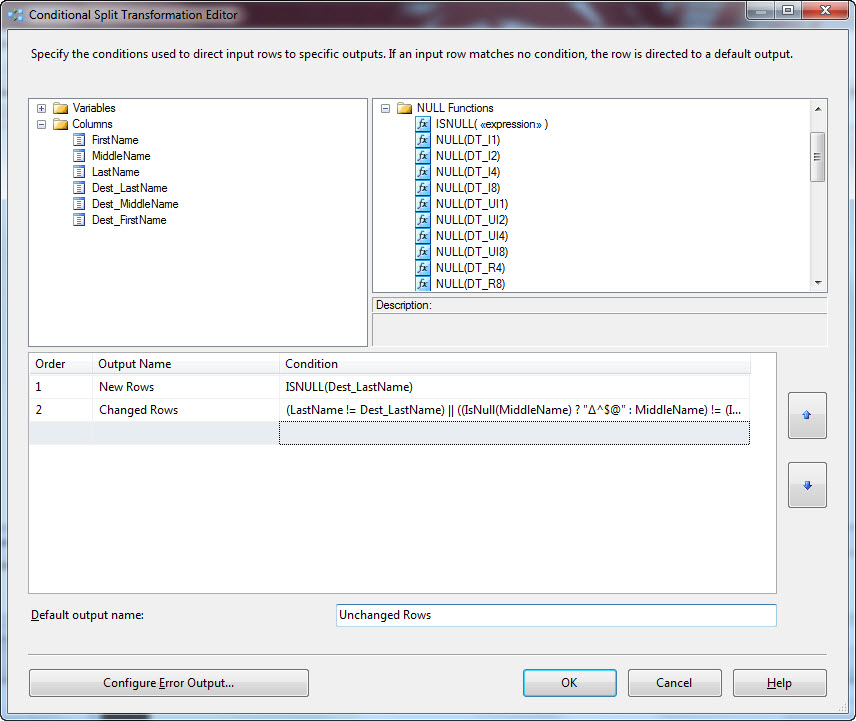
Configuring the default output involves simply renaming the Default output buffer to Unchanged Rows.
Conclusion
That’s it! The Filter portion of this Data Flow Task is built!
:{> Andy
Obviously the idea of this is to showcase the conditional Split transform, but another way of handling non-matching rows (new rows in the above example) is to configure the Error Output path of the Lookup transform.
By setting the Error disposition of the Lookup Output to ‘Redirect Row’, non-matching rows can be sent down a different data flow path.
Hi Lempster,
While technically correct, I find redirecting rows using an error path visually misleading. For this same reason, I do not recommend error precedence constraints in the Control Flow. Even if the error is managed properly in the context of SSIS, logs will reflect an error occurred. The convenient deflection against these arguments is "we should train everyone…". I diagree – people already get what an error is (they’ve already been trained). Why no leverage their existing knowledge in the context of SSIS, write a few more lines of code, and reduce the potential friction of misunderstanding?
Just a thought,
Andy
hi! i like your alternative.
And if you want to use with New Rows (to blank tables). What to do?
Very helpful post
I would like to add my comment on Lempster’s comment because this approach doesnt work if there is no matching data. It will return an error and never will be forwarded. Therefore either error path or connecting destination with “non matching” option is the best way