

Yesterday I was coding away, deep into using C# to decompress and parse Excel XML so I could read data from a specific worksheet in a workbook on a server without Excel objects installed, when I saw the following on Twitter:
For those of you who do not already know…
I Don’t Switch Contexts Well
I wasn’t wrong.
I just wasn’t thinking… yet.
Plus (blogger tip), if you want your blog to help people, be on the lookout for statements like, “I can’t find this anywhere…” When you find one, blog about that topic.
I searched and found some promising Parquet SSIS components available from CData Software and passed that information along. I shared my inexperience in exporting to parquet format and asked a few friends how they’d done it.
I thought: How many times have I demonstrated Azure Data Factory and clicked right past file format selection without giving Parquet a second thought? Too many times. It was time to change that.
The request in the tweet is threefold:
- Read data from SQL Server.
- Write the data to a Parquet file.
- Stay on-premises.
Steps 1 and 2
Steps 1 and 2 can be accomplished in Azure Data Factory without much hassle. The steps are:
Create a pipeline:
Add a Copy Data activity:
Configure a SQL Server data source:
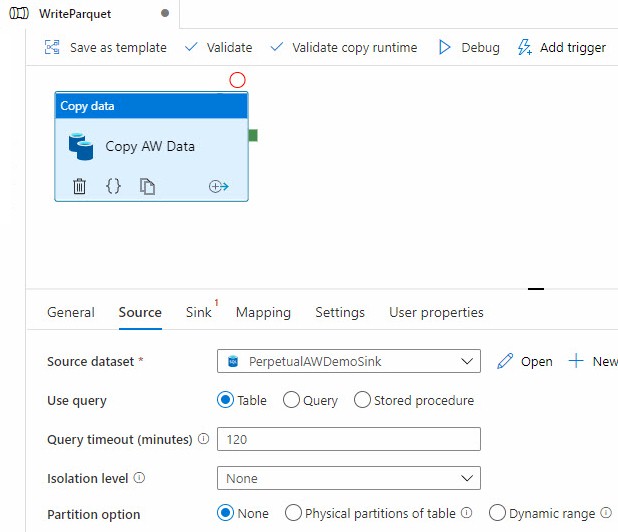
Configure a Parquet sink:
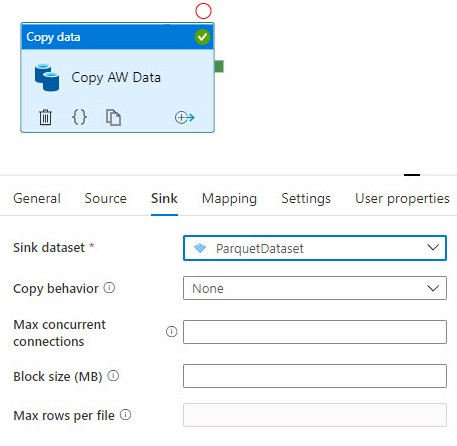
I used a storage account configured for Azure Data Lake as my target, and you can find details on configuring ADLS and using Parquet with ADF at Microsoft docs.
Step 3
Staying on-premises was the tricksy part of this request. I decided to create a C# (.Net Framework) console application to test the concepts. I also decided to use Parquet.Net:
I found some helpful C# on Darren Fuller‘s post titled Extracting data from SQL into Parquet. I modified Darren’s code some and was able to export a dataset from the AdventureWorks2019.Person.Person database to a Parquet file using the following code:
I apologize for the formatting. You should be able to copy and paste this code into a C# (.Net Framework) console app and have at it. The code can also be adapted for an SSIS Script Task.
Conclusion
I tested the output Parquet file by uploading the output file to Azure Blob Storage, creating a test target table, creating a test ADF pipeline, and then loading the data from the file into the table:
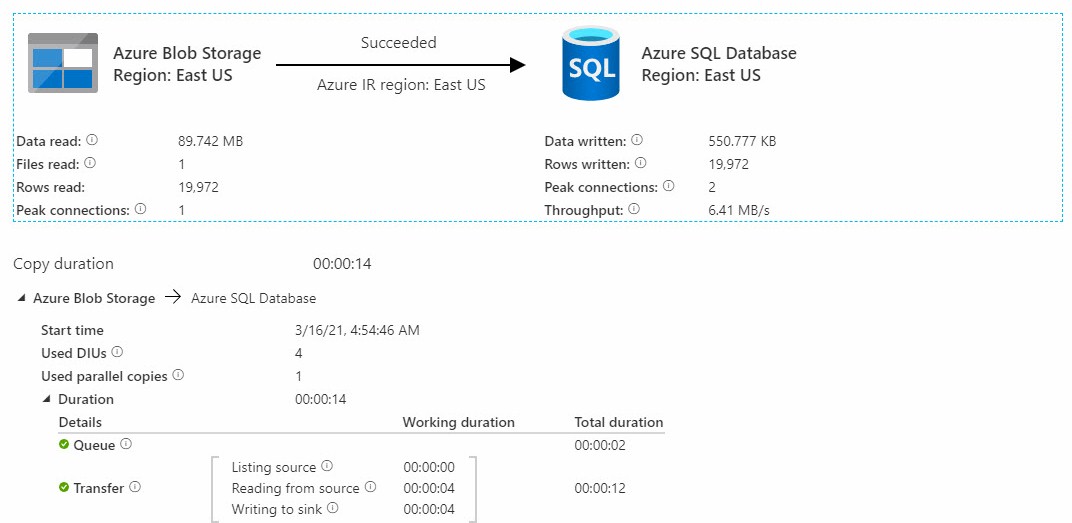
The load succeeded and a test query showed my data.
I hope this helps.
Peace.
We have used ‘external tables’ aka Polybase to extract data into Parquet files on prem. Once external table (Parquet file) is defined is just a simple insert into .. lot less coding requried..
Can you please explain more how you did it , as we also have a requirement to do this.
For your original question “Yesterday I was coding away, deep into using C# to decompress and parse Excel XML so I could read data from a specific worksheet in a workbook on a server without Excel objects installed”
feel free to give a try to the following: http://spreadsheetlight.com/
It actually does work very nicely. And if you need help scripting it using Powershell here is assembly wrapper https://github.com/MironAtHome/OpenOfficeExcelLibrary.git
You can also do this easily with sling (https://slingdata.io). See Below.
# set connection via env var
export mssql=’sqlserver://…’
# test connection
sling conns test mssql
# run export for many tables
sling run –src-conn mssql –src-stream ‘my_schema.*’ –tgt-object ‘file://{stream_schema}/{stream_table}.parquet’
# run export for one table
sling run –src-conn mssql –src-stream ‘my_schema.my_table’ –tgt-object ‘file://my_folder/my_table.parquet’
Use polybase if available or python + duckdb.
Get a recordbatchreader (https://github.com/pacman82/arrow-odbc-py) and pass it to duckdb to copy the data to parquet in a streaming way.