

Unlock the potential of your cloud-data strategy and step into the future with confidence. Join us LIVE on 17 Dec 2025 for “A Day of Azure Data Factory”, a powerful 1-day online training designed for professionals like you aiming to master Azure Data Factory (ADF). This hands-on session, led by industry expert Andy Leonard, covers: …
Continue reading Join me 17 Dec 2025 for A Day of Azure Data Factory Live, 1-Day Training
Category:ADF
Metadata-Driven Fabric Data Factory Pipeline Orchestration From ADF
Blog Post Note / Disclaimer / Apology: This is a long blog post. It makes up for the length by being complex. I considered ways to shorten it and to reduce its complexity. This is the best I could do. – Andy Visit the landing page for the Data Engineering Execution Orchestration Frameworks in Fabric Data …
Continue reading Metadata-Driven Fabric Data Factory Pipeline Orchestration From ADF
Regarding Return Pipeline Value Data Type
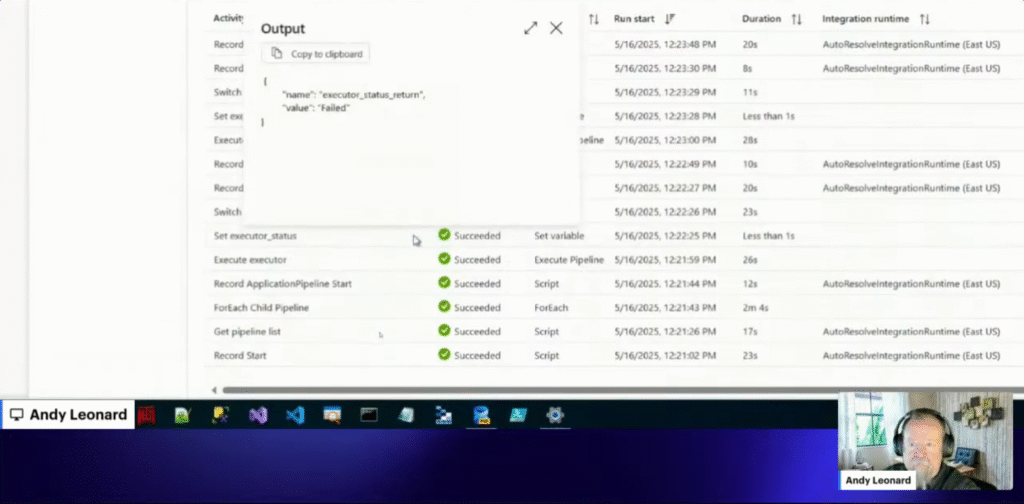
On last week’s exciting and thrilling episode of Data Engineering Fridays, I was stymied for a bit. You can watch me struggle with my code here – the struggle lasted for a while. I eventually figured it out. As an aside: I absolutely love streaming live-coding! Believe it or not, failing is one of my favorite parts. …
Continue reading Regarding Return Pipeline Value Data Type
Fabric Data Factory Pipeline Execution From Azure Data Factory
Visit the landing page for the Data Engineering Execution Orchestration Frameworks in Fabric Data Factory Series to learn more. I must begin this post with a simple – perhaps profound – statement: Koen Verbeeck (LinkedIn | @Ko_Ver) is a talented data engineer. Here’s why I begin this post with such a statement. If you’ve been following my …
Continue reading Fabric Data Factory Pipeline Execution From Azure Data Factory
Configure Azure Security for the Fabric Data Factory REST API

Visit the landing page for the Data Engineering Execution Orchestration Frameworks in Fabric Data Factory Series to learn more. I must begin this post with a simple – perhaps profound – statement: Koen Verbeeck (LinkedIn | @Ko_Ver) is a talented data engineer. Here’s why I begin this post with such a statement. Koen’s Great Idea …
Continue reading Configure Azure Security for the Fabric Data Factory REST API
Announcing Data Engineering Fridays!

I’m excited to announce Data Engineering Fridays! I can hear some of you thinking, … “What are Data Engineering Fridays, Andy?” That’s an awesome question! I’m glad you asked. Data Engineering Fridays is a weekly stream, between 24 May and 23 Aug 2024, in which I lead a discussion about data engineering-related topics. The 24 …
Continue reading Announcing Data Engineering Fridays!
Join Me at the PASS Data Community Summit 2023!

I am honored to deliver Designing an Execution Framework for Azure Data Factory at the PASS Data Community Summit 2023 in Seattle Washington 15 Nov 2023 at 3:15 PM PT in room 6C! From the Abstract If your enterprise manages dozens of ADF pipelines, an execution framework is unnecessary overhead. If your enterprise manages thousands …
Continue reading Join Me at the PASS Data Community Summit 2023!
Build a Get-Subscription ADF Pipeline Using Pipeline Return Value Course Now Available

I am excited to announce the availability of Build a Get-Subscription ADF Pipeline Using Pipeline Return Value, a new Azure QuickStart course! Access the new course – along with all my recorded training for one year – by subscribing to Premium Level. Additional access options include: Azure QuickStart Premium – Access all Azure QuickStart training …
Continue reading Build a Get-Subscription ADF Pipeline Using Pipeline Return Value Course Now Available
Presenting Introduction to ADF at Hampton Roads Azure Users Group at 6:00 PM 10 Oct 2023!

I am honored to present Introduction to ADF at Hampton Roads Azure Users Group at 6:00 PM 10 Oct 2023! I’ll be there live and in-person. Abstract Azure Data Factory – ADF – is a cloud data engineering solution. ADF version 2 sports a snappy web GUI (graphical user interface) and supports the SSIS Integration …
Continue reading Presenting Introduction to ADF at Hampton Roads Azure Users Group at 6:00 PM 10 Oct 2023!
Return a Value from an ADF Pipeline Course Now Available

I am excited to announce the availability of Return a Value from an ADF Pipeline, a new Azure QuickStart course! Access the new course – along with all my recorded training for one year – by subscribing to Premium Level. Additional access options include: Azure QuickStart Premium – Access all Azure QuickStart training plus Premium …
Continue reading Return a Value from an ADF Pipeline Course Now Available