

09 Aug 2023 Update: Yitzhak Khabinsky and I met via Microsoft Teams to continue the conversation that started in the comments section of this post and was continued on LinkedIn. There will likely be more to come…
Why Use XML to Transfer Data?
I asked Brave Search, “Why use XML?” Brave responded with a Summarizer section which explained:
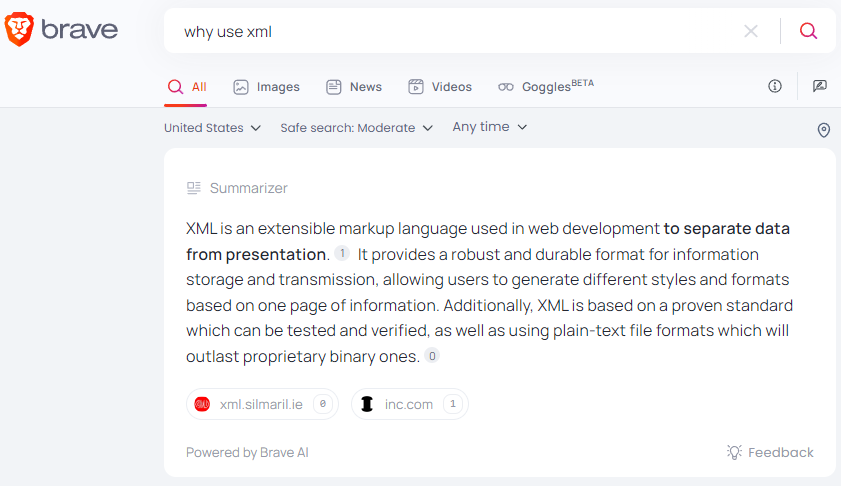
“XML is an extensible markup language used in web development to separate data from presentation. It provides a robust and durable format for information storage and transmission, allowing users to generate different styles and formats based on one page of information. Additionally, XML is based on a proven standard which can be tested and verified, as well as using plain-text file formats which will outlast proprietary binary ones.”
There are some sound reasons to employ XML listed in that Summarizer blurb.
An aside: Brave makes a search engine and a browser. Both boast private searching and browsing. Less than one week ago (at the time of this writing), Brave added a “Summarizer” section to its search results, powered by Brave AI (learn more here).
<AndyTranslation>XML is an acronym for eXtensible Markup Language. XML permits data definition and data values in a self-describing page of data. XML tags mark the beginning and end of columns in a row, with the data value for the row-column stored between the opening and closing tags. The XML format is designed to vary to match specific use cases. </AndyTranslation>
In T-SQL (SQL Server’s SQL), one uses the “FOR XML mode” clause to extract data in different XML formats.
Some Examples
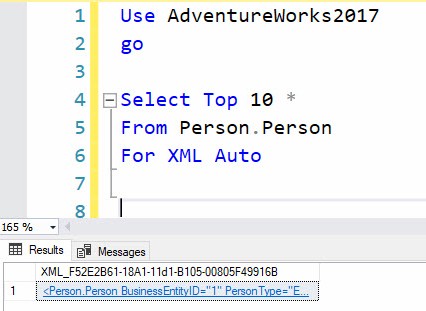
The following query results are converted to XML using the FOR XML AUTO clause:
Use AdventureWorks2017
go
Select Top 10 *
From Person.Person
For XML Auto
The result displays in SQL Server Management Studio (SSMS) as:
If the “link” in the single returned row is clicked, SSMS presents a better-formatted view of the XML:

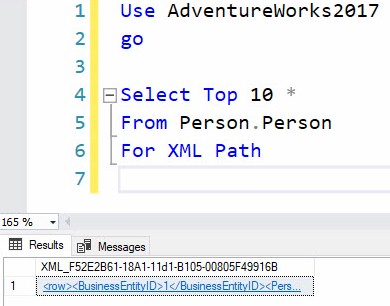
Change the FOR XML clause from “Auto” to “Path” and the resulting format changes:
Use AdventureWorks2017
go
Select Top 10 *
From Person.Person
For XML Path
The result displays in SQL Server Management Studio (SSMS) as:
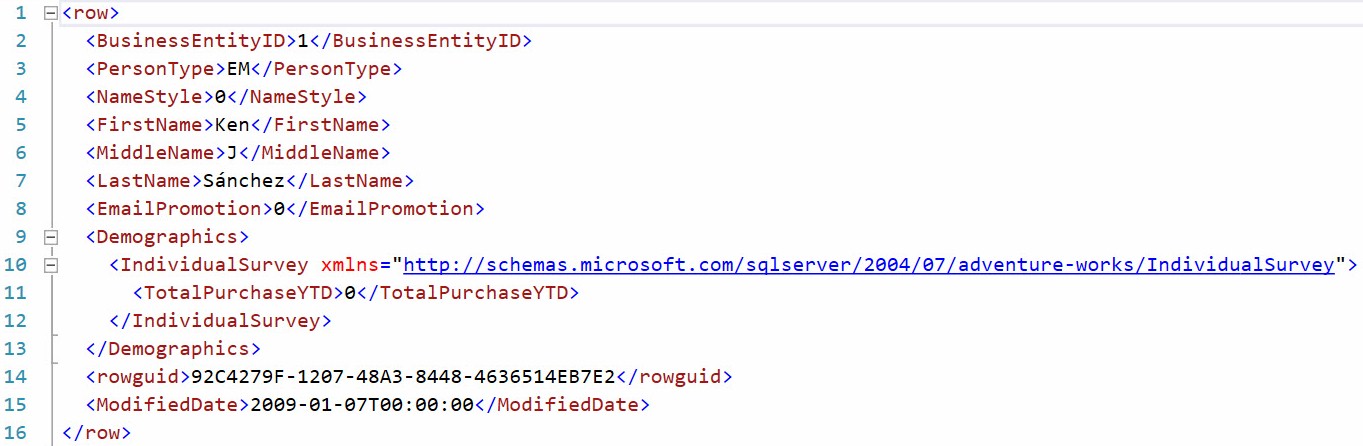
Clicking the “link” in the single returned row presents a better-formatted view of the XML:
Cool? Cool. I can hear some of you thinking,…
“I Do Not See A Problem, Andy.”
You are correct. The reason you do not see a problem is because, well, I haven’t show you a problem. Yet.
From a data engineering perspective, I find XML’s self-describing format its most powerful feature. The reason I find the self-describing format so powerful is: XML allows me to send data rows and include data definition metadata in the same document. Most of the time, the data – although presented in schemata that vary by row – is related – such as Orders and OrderItems, or Patient and PrescribedMedications.
Way back in 2010, I blogged about a design pattern for loading rows of data presented in Comma-Separated Values (CSV) format – rows that present columns in different schemata – in a post titled SSIS Design Pattern: Loading Variable-Length Rows. In the post, the (CSV) rows present a somewhat self-describing format (quasi-self-describing? bounded-chaos-self-describing? Naming things is hard, even when you are published and possess a License to Spell). This pattern, along with the straightforward XML data shown so far in this post, share an attribute: the data definition (format, or schemata) is stable and predictable.
Unpredictable Schemata
What happens if the data definition (schemata) is unpredictable? Well, then you need a self-describing data format such as XML. JavaScript Object Notation (JSON) delivers self-describing data, as well. This is one reason my friend and brother from another mother, Kevin Hazzard, describes JSON as “hipster XML.”
Cool? Cool. I continue to hear some of you thinking, …
“I Still Do Not See A Problem, Andy.”
The reason you still do not see a problem is because, well, I still haven’t show you a problem. Yet.
A Question
If you are sending me (or some other hapless victim data engineer) lots of data that resides in a stable schema – one in which the number, order, data type, etc. of the columns never change – using XML, I have a question:
Why?
Why are you using XML to transmit this data?
Do you realize the column names, whether represented as attributes or tags, are repeated repeatedly in what is essentially a large (and made even larger by the repeated repetition) file that repeatedly repeats the name of these column names? I submit this is acceptable if you are being paid by the byte, because a data engineer’s got bills to pay like everybody else. But if that’s not the case, why?
<AndyScreed>Is XML a popular data exchange format? Does everybody use XML? I’ve heard similar arguments. I’ve never heard them from a data engineer, mind you. It’s always been from developers. If you are a developer, have you considered listening to, I don’t know, anyone else on the planet – especially people who specialize in (please be seated), A DIFFERENT JOB? Yall realize there are these other people out there? People who are not developers? But have spent as many (or even more) months, years, or even decades doing something different from developing software? Right? And some of them know things that (still seated?) you do not know about their particular specialty. Before you load 0xHUFF into your internal buffer, yes; we all know you know more about developer stuff than we data people (especially we <gasp>older</gasp> data people). And we’re happy to acknowledge it when we’re allowed to get in a word edgewise. </AndyScreed>
Returning to “Helpful Andy”…
Hey. I was being helpful. A little tough love now and then is a good thing. Plus, I am speaking from experience. I acted the exact same way when I was a developer.
My suggestion is to avoid the useless and frustrating and useless repeated repetition (see what I did there?) of sending XML if a list of comma-separated column names in line 1 of a text file will suffice; please use CSV, tab-separated values, or even fixed-width or ragged-right data file formats. Unless you have a compelling reason (they exist) to transmit data in a self-describing format, please opt for human- and machine-readable data formats that consume less space and bandwidth.
Conclusion
Love ya.
Mean it.
Peace.
:{>
JSON: XML Lite
Hi George,
I concur.
:{>
*.csv/txt flat files always have host of problems where column delimiters, column separators, invisible characters like null terminators \0, special characters based on encoding, and line breaks are in the middle of the actual data. Or data elements are missing completely.
The most reliable format for data feeds is XML enforced by an XSD. An XSD plays a role of a data contract between sender and receiver. It will guarantee proper data format/shape, data types, cardinality, and enforce data quality.
Hi Yitzhak,
Thank you for reading my blog and for sharing your thoughts!
All flat file formats are subject to bad formats… including XML.I maintain if the schemata is stable, XML is not worth the hassle. Agree to disagree.
Thank you!
Update
Short version: I was wrong and Yitzhak was correct.
Longer version: XSD 1.1 is super cool and a valid reason for using XML to transport data. In my years of loading data, I cannot recall a single instance where an XSD was supplied with the XML; I ended up generating XSD’s. My experience skewed my opinion of XML for data transport. Yitzhak helped me see the value of XML with XSD’s.
Thank you, Yitzhak!