

A number of folks are using the SSIS Framework Community Edition. I know because I continue to get interesting questions about it! Before I write more, I’d like to invite users to the DILM Suite Slack channel for Community Edition. If you cannot join, please let me know (andy.leonard@dilmsuite.com) and I will invite you!
For those who may not know, SSIS Framework Community Edition is free and open source.
I’m writing about parallel execution in SSIS Framework Community Edition because I’ve received more than one question about parallel execution in the past several days. Rather than copying and pasting responses, I figured I’d write a post about it and copy and paste the URL!
This is a long post and you may not be interested in reading all of it. It can be divided into three sections:
- One scenario to consider when parallelizing loads in SSIS (which starts right after this list) – laden with data integration theory
- Ways to parallelize loads in SSIS with and without a Framework – practical answers to the question at hand
- Thoughts regarding designing a Framework to automate parallel execution
Parallel Execution in SSIS
If you search online for ways to improve SSIS performance you will find myriad tips and tricks. Most of them are valid, some are not, and at least one has been invalid since mid-2006 (and it may be the one you find first). Why is this so? The internet is an echo chamber, and search engines are the medium through which the echoes travel.
One tip you will doubtless encounter is: Execute SSIS packages in parallel to improve performance. This is excellent advice.*
*Please note the asterisk. I place an asterisk there because there’s more to the story. Lots more, in fact. I can hear thinking, “What more is there to the story, Andy?” I’m glad you asked.
Dependencies and Race Conditions
Sit a spell and let Grandpa Andy tell yall a story about some data integratin’.
Suppose for a minute that you’ve read and taken my advice about writing small, unit-of-work SSIS packages. I wouldn’t blame you for taking this advice. It’s not only online, it’s written in a couple books (I know, I wrote that part of those books). One reason for building small, function-y SSIS packages is that it promotes code re-use. For example, SSIS packages that perform daily incremental loads can be re-used to perform monthly incremental loads to a database that serves as a data mart by simply changing a few parameters.
Change the parameter values and the monthly incremental load can load both quarterly and yearly data marts.
You want better performance out of the daily process, so you read and implement the parallel execution advice* you’ve found online. For our purposes let’s assume you’ve designed a star schema instead of one of those pesky data vaults (with their inherent many-to-many relationships and the ability to withstand isolated and independent loads and refreshes…).
You have dependencies. The dimensions must be loaded before the facts. You decide to manage parallelism by examining historical execution times. Since you load data in chronological order and use a brute-force change detection pattern, the daily dimension loads always complete before the fact loads reach the latest data. You decide to fire all packages at the same time and your daily execution time drops by half, monthly executions time drops to 40% of its former execution time, and everyone is ecstatic…
…until the quarterly loads.
The fact loaders begin failing. You troubleshoot and see the lookups that return dimension surrogate keys are failing to find a match. By the time you identify and check for the missing surrogate keys, you find them all loaded into the dimensions. What is going on?
What Happened
Facts are, by nature, “skinny.” Although you may load many more fact rows when loading a star schema, those rows are composed mostly of numbers and are not very wide.
When an SSIS Data Flow Task loads rows, it places the rows in buffers in RAM. You can visualize these buffers as buckets or boxes. If you choose boxes, think of the buffers as rectangles that can change shape. Some rectangles are square (remember, from high school geometry?), some are wide and not tall, some are tall and not wide. No matter what, the area of the rectangle doesn’t change although the shape will change based on the shape of each table. The shape of the buffer is coupled to the shape of the table – and is specifically driven by the length of the table row.
Aside: When I talk about this in Expert SSIS, I refer to this as “thinking like a Data Flow.”
One result is that fact loaders, when they start, most often load rows differently compared the dimension loaders. In engineering-speak, fact and dimension loaders have a different performance characteristic. I learned about characteristics studying electronics. When I became an electrician in a manufacturing plant, repairing and later designing and building electrical control systems, I learned about race conditions, which is what we have here.
Because the SSIS Data Flow Task buffers data and because dimensional data are most often wide, dimensions load fewer rows per buffer. Conversely, because fact data are narrow, facts load more rows per buffer.
There exists a (hidden) threshold in this scenario defined by when the fact loaders (executing in parallel with dimension loaders) reach new rows (which reference new dimension surrogate keys) compared with when the dimension loaders reach and load their new rows, thereby assigning said new rows their dimensional surrogate keys.
At lower row counts – such as daily or even monthly loads – the difference between dimensional and fact loader performance characteristics remains below the threshold, and everything appears peachy.
The race condition I describe here occurs because, at higher row counts, the dimensions load slower – much slower – than the facts load. The difference in performance characteristics crosses the threshold when one or more fact loaders reach new rows for which corresponding dimensions have not yet been loaded.
This is a race condition.
Not a Late-Arriving Dimension
Now, you may read this scenario and think, “No Andy, this is a late-arriving dimension or early-arriving fact.” It’s not. Both dimension and fact source records are present in the source database when this load process begins. Late-arriving facts occur when the dimension load starts before a particular row in the dimension has been added, and the fact row referencing that particular dimension record is added after the dimension load completes but before the fact load starts.
Inferred Members
But since you brought this up, is there a solution for late-arriving dimensions? Yep. Inferred members.
Let’s say you have implemented inferred member logic in your fact load and you encounter this race condition. What happens? Remember, the dimension and fact loaders are running in parallel and they work just fine for daily and monthly processing. In our scenario, the quarterly load crosses the threshold and causes a race condition.
When the fact loader reaches a dimension record that has not yet been loaded, the dimension loader is still running.
If you implement inferred member logic, you insert a row into the dimension – inserting the natural key which generates an (artificial) surrogate key – which is then returned to the fact loader so that the fact can continue loading without failure or interruption. While inferred members is a cool and helpful pattern, what happens when the dimension loader catches up? Hopefully, you have either a unique constraint on the natural key (and you haven’t disabled it to speed up the dimensional load process…another idea I and others have shared that you may have read) or you’ve incorporated inferred logic into the dimension loaders so that you check for the existence of the natural key or business key first – which updates the dimension row if the natural key already exists (and adds logic which further complicates and slows down the dimension loading process… there’s no free lunch…). Otherwise, you have a failed dimension loader execution or (worse, much worse), your race condition coupled with missing design elements combine to create duplicate dimension rows (which render the data mart useless).
Solving the Race Condition
The easy way to solve for race conditions – especially hidden race conditions – is to execute loaders serially. This goes directly against the SSIS performance advice of executing loaders in parallel.
Applied in SSIS Framework Community Edition
This is why SSIS Framework Community Edition defaults to serial execution.
“Great Andy, But What If I Need To Load In Parallel Using A Framework And I Mitigate Race Conditions?”
Enter the SSIS Design Pattern named the Controller Pattern. A Controller is an SSIS package that executes other SSIS packages. Controllers can be serial or parallel, or combinations of both. I’ve seen (great and talented) SSIS architects design frameworks around specific Controllers – building a Controller for each collection of loaders related to a subject area. SSIS Framework Community Edition ships with a generic metadata-driven serial controller named Parent.dtsx, found in the Framework SSIS solution.
Specific Controller Design
A specific Controller can appear as shown here (click to enlarge):
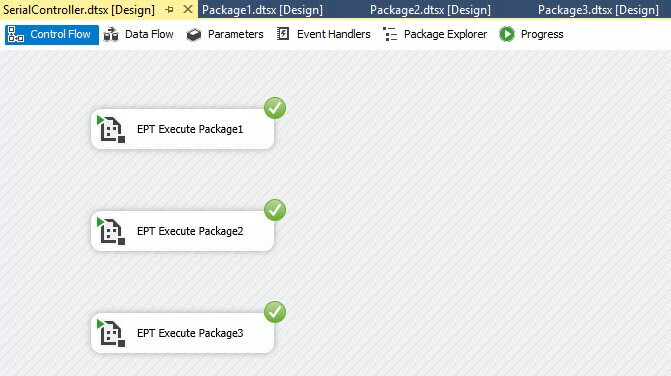
This controller achieves parallel execution. One answer to the question, “How do I execute packages in parallel?” is to build a specific controller like this one.
Advantages
- Works
- Simple and straightforward, uses out-of-the-box Execute Package Task
Disadvantages
- “All Executions” Catalog Report is… misleading
How is the All Executions Report misleading? If you build and deploy a project such as SerialControllers SSIS project shown here – and then execute the SerialController.dtsx package – the All Executions reports only a single package execution: SerialController.dtsx (click to enlarge):

We see one and only one execution listed in the All Executions report, but if we click on the link to view the Overview report, we see each package listed individually:
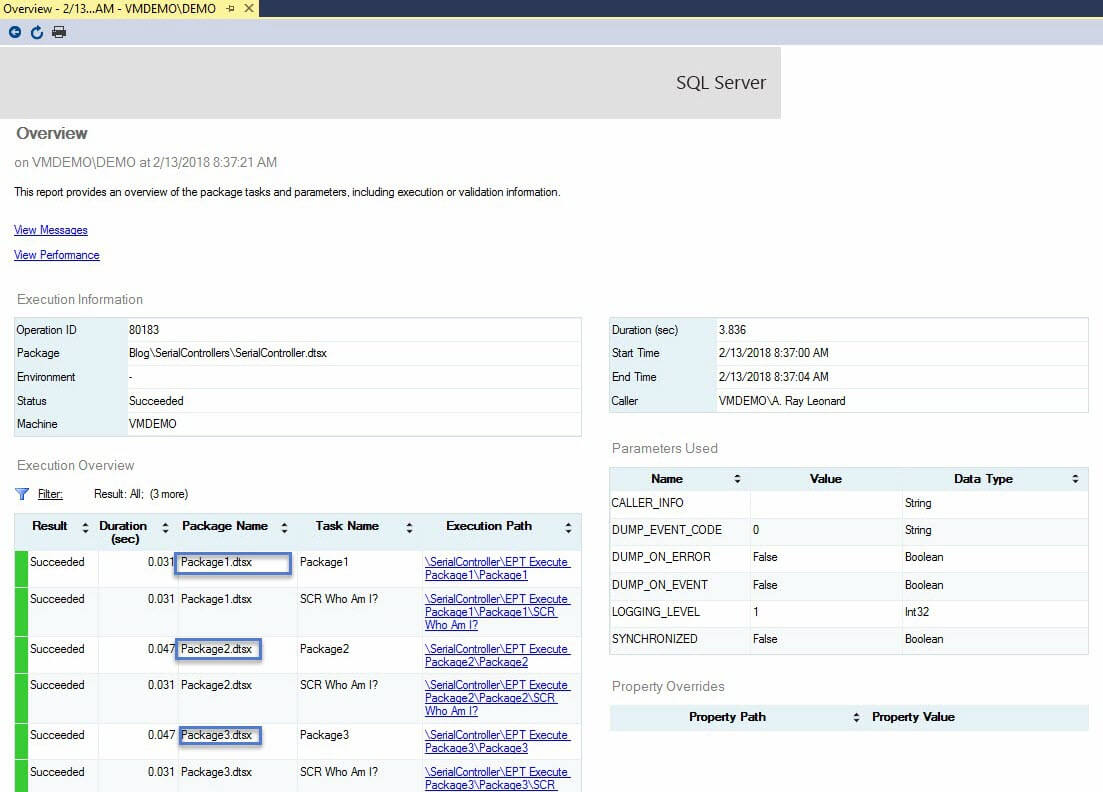
All Executions accurately reflects an important aspect of the execution of the SerialController.dtsx SSIS package: The execution of this package – and the packages called by SerialController.dtsx – share the same Execution ID value. This is not necessarily a bad thing, but it is something of which to be aware.
Specific Controller Design in SSIS Framework Community Edition
A specific Controller built using SSIS Framework Community Edition can appear as shown here:
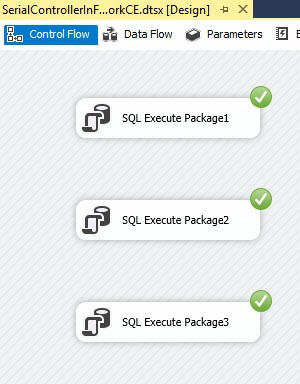
This controller uses Execute SQL Tasks instead of Execute Package Tasks. The T-SQL in the Execute SQL Tasks call a stored procedure named custom.execute_catalog_package that is part of SSIS Framework Community Edition.
One answer to the question, “How do I execute packages in parallel using SSIS Framework Community Edition?” is to build a controller such as this.
Advantages
- Works
- All Executions report is accurate
Disadvantages
- Adds complexity
The All Executions Report is no longer misleading. If you build and deploy a project such as SerialControllersInFrameworkCE SSIS project shown here – and then execute the SerialControllerInFrameworkCE.dtsx package – the All Executions reports each package execution (click to enlarge):
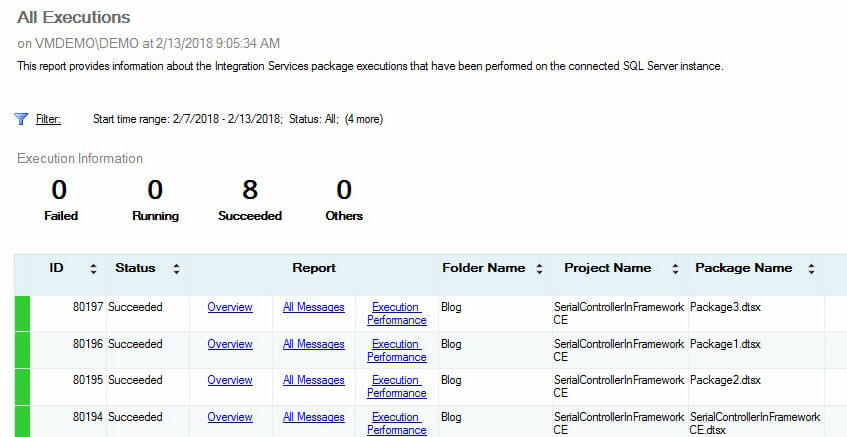
We now see one execution listed in the All Executions report for each package. As before, All Executions accurately reflects an important aspect of the execution of the SerialControllerInFrameworkCE.dtsx SSIS package: The execution of the Controller and each Child package now have distinct Execution ID values.
When using specific Controllers with an SSIS Framework, it’s common to create a single-package SSIS Application that simply starts the Controller, and let the Controller package call the child packages. Parent.dtsx in SSIS Framework Community Edition is a generic metadata-driven Controller, but it doesn’t mind executing specific Controllers one bit!
Once Upon A Time…
Not too long ago, Kent Bradshaw and I endeavored to add automated parallel package execution to our Commercial and Enterprise SSIS Frameworks. We achieved our goal, but the solution added so much complexity to the Framework and its associated metadata that we opted to not market the implemented solution.
Why? Here are some reasons:
Starting SSIS packages in parallel is very easy to accomplish in the SSIS Catalog. The SYNCHRONIZED execution parameter is False by default, and that means we could build a controller package similar to the SerialControllerInFrameworkCE.dtsx SSIS package – with precedence constraints between each Execute SQL Task, even – and the SSIS Catalog would start the packages in rapid succession. In some scenarios – such as the scenario discussed in the first section of this post – this then becomes a race condition engine.
Why?
Because controlling only when packages start is not enough to effectively manage race conditions. To mitigate the race condition described earlier I need to make sure the dimension loaders complete before starting the fact loaders. A (much simplified) Controller for such a process could appear as shown here (click to enlarge):
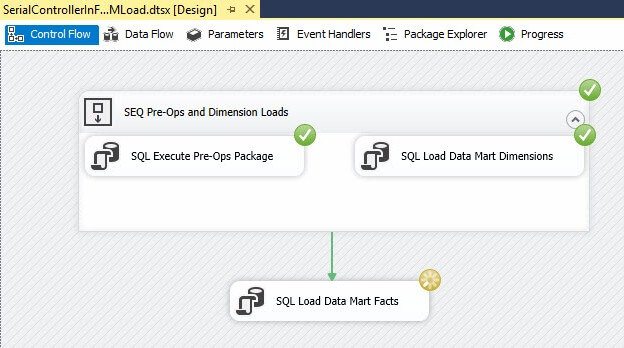
I grabbed this screenshot after the dimension loader and some (vague) pre-operations process have completed in parallel, but while the fact loader is still executing. Please note the combination of the Sequence Container and precedence constraint which ensure the fact loader does not start executing until the dimension loader execution is complete. The sequence container creates a “virtual step” whereby all tasks within the container must complete before the sequence container evaluates the precedence constraint. Since each task inside this container starts an SSIS package (and since the SYNCHRONIZED execution parameter is set to True by default in SSIS Framework Community Edition), nothing downstream of this container can begin executing until everything inside the container has completed executing. This is how we avoid the race condition scenario described earlier.
How does one automate this process in a framework?
It’s not simple.
The method Kent and I devised was to create and operate upon metadata used to define and configure a “virtual step.” In SSIS Framework Community Edition the Application Packages table is where we store the Execution Order attribute. We reasoned if two Application Package entities shared the same value for Execution Order, the associated package(s) (I’m leaving out some complexity in the design here, but imagine executing the same package in parallel with itself…) compose a virtual step.
In a virtual step the packages would start together, execute, and not proceed to the next virtual step – which could be another serial package execution or another collection of packages executing in parallel in yet another virtual step – until all packages in the current virtual step had completed execution. Here, again, I gloss over even more complexity regarding fault tolerance – we added metadata to configure whether a virtual step should fail if an individual package execution failed.
This was but one of our designs (we tried three). We learned managing execution dependency in a framework is not trivial. We opted instead to share the Controller pattern.
Conclusion
In this post I wrote about some data integration theory. I also answered a question I regularly receive about performing parallel loads using SSIS Framework Community Edition. I finally covered some of the challenges of automating a solution to manage parallel execution of SSIS packages in a Framework.
One thought on “Parallel Execution in SSIS Framework Community Edition”