
I am honored to announce the latest version of SSIS Catalog Browser is available for (free!) download. Updates in v0.9.14.0: Bug fixes. No longer mixing package parameter references with project parameter references in the Values Everywhere feature. Check it out today! Want to Learn Azure Data Factory (from me)? I’m delivering a full day of …
Continue reading SSIS Catalog Browser v0.9.14.0 is Available
Category:Azure-SSIS
Deploy an SSIS Project to an ADF Azure-SSIS IR Course Now Available

I am excited to announce the availability of Deploy an SSIS Project to an ADF Azure-SSIS IR, a new Azure QuickStart course! Access the new course – along with all my recorded training for one year – by subscribing to Premium Level. Additional access options include: Azure QuickStart Premium – Access all Azure QuickStart training …
Continue reading Deploy an SSIS Project to an ADF Azure-SSIS IR Course Now Available
Build a Pipeline to Stop an ADF Azure-SSIS IR Course Now Available

I am excited to announce the availability of Build a Pipeline to Stop an ADF Azure-SSIS IR, a new Azure QuickStart course! Access the new course – along with all my recorded training for one year – by subscribing to Premium Level. Additional access options include: Azure QuickStart Premium – Access all Azure QuickStart training …
Continue reading Build a Pipeline to Stop an ADF Azure-SSIS IR Course Now Available
Failed Get Parameter Info Error in Azure-SSIS
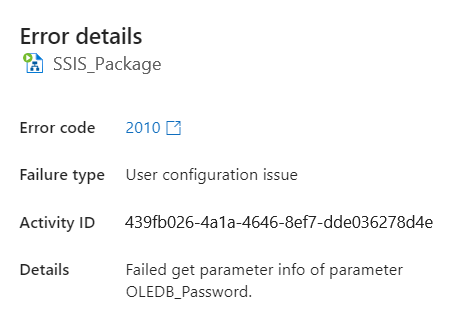
Have you encountered this error: “Failed Get Parameter Info of parameter ____”? I ran into this error a couple times while consulting for a client to lift and shift SQL Server Integration Services (SSIS) to Azure Data Factory (ADF). The Most Likely Fix Make sure the Azure-SSIS integration runtime is running: Launch Azure Data Factory …
Continue reading Failed Get Parameter Info Error in Azure-SSIS
Laid Off? Or the Beginning of Your Next Opportunity?

Updates: The “opp23” limited-time offer has expired. I may make similar offers in the future. The best way to learn of offers from me is to subscribe to my mailing list and check the checkbox labeled “I would like to receive more information about products, services, events, communications, and offers.” If you signed up for …
Continue reading Laid Off? Or the Beginning of Your Next Opportunity?
Azure-SSIS Express Custom Setup License Key Textbox Update
Back in June 2022, I was honored to deliver a webinar along with the good people on the SolarWinds Task Factory team. During that presentation, I noticed (and I may have even commented on) the License key textbox not being masked when adding Task Factory to an Azure-SSIS integration runtime. I sent a note to the …
Continue reading Azure-SSIS Express Custom Setup License Key Textbox Update
Presenting Master the Fundamentals of ADF at SQL Saturday Boston!

I am honored to deliver Master the Fundamentals of ADF at SQL Saturday Boston 2022 (#1031) 7 Oct 2022! Abstract Azure Data Factory, or ADF, is an Azure PaaS (Platform-as-a-Service) that provides hybrid data integration at global scale. Use ADF to build fully managed ETL in the cloud – including SSIS. Join Andy Leonard – …
Continue reading Presenting Master the Fundamentals of ADF at SQL Saturday Boston!
Join Me at the PASS Data Community Summit 2022!

I am honored to deliver two training sessions at the PASS Data Community Summit 2022: A Day of Azure Data Factory is a full-day pre-conference session scheduled for Monday, 14 Nov 2022. In this session I cover version control integration, copying data, using parameters and metadata, design patterns (of course!), and more! Introduction to Azure …
Continue reading Join Me at the PASS Data Community Summit 2022!
Azure-SSIS Supports SSIS 2017 Only

With the recent public preview release of Synapse-SSIS, I want to remind SSIS developers that Azure-SSIS integration runtimes – be they configured in Azure Data Factory (ADF) or in Azure Synapse Analytics – support only SSIS 2017 packages. Errors most often occur when executing SSIS packages that contain script tasks or script components. If you deploy …
Continue reading Azure-SSIS Supports SSIS 2017 Only
An SSIS Catalog Environment Task

In this post Andy shares thoughts about a new custom SSIS task I’ve written to set SSIS package variable values from SSIS Catalog Environment Variable values.